Thoughts On Spaces In Workspace And Column Names in Microsoft Fabric
My thoughts and recommendations on Workspace and Column names in Microsoft Fabric
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
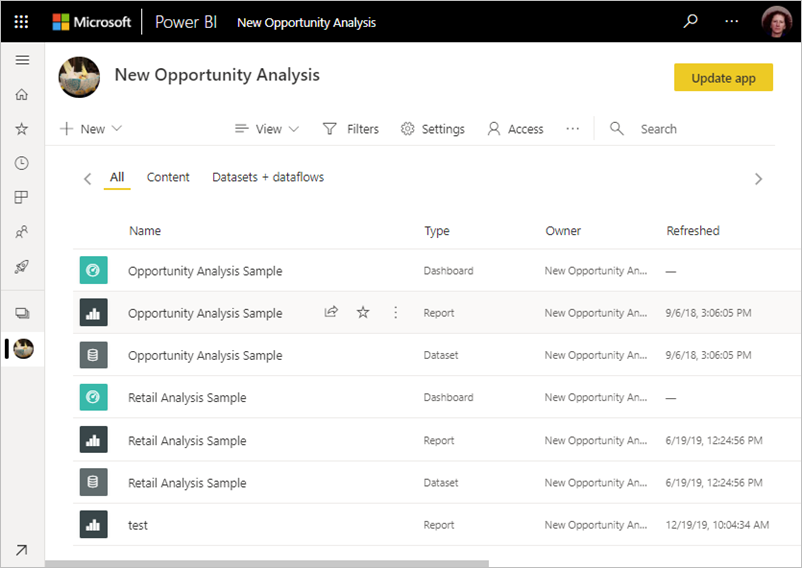
If you are coming to Microsoft Fabric from Power BI, you will know that it's very common to have spaces in Workspace, Table and Column names to make them user-friendly. Power BI has no restriction on including spaces in names. For example, if you look at the official MSFT documentation page about Workspaces (see below), the workspace is named New Opportunity Analysis. This makes the name, easy to read and business-friendly. In Microsoft Fabric, there is no restriction on white spaces in workspace names either. However, in Fabric, removing the spaces will help in certain situations.
Similarly, in Power BI datasets, it's a best practice to make table and column names business-friendly for other developers/users to easily query the tables, and build reports in Power BI or Excel. In Fabric, you will first save the table in Delta format and then you will use it in Import, Direct Query or Direct Lake mode. In an ideal scenario, the table and column names in delta tables should be the same as the Power BI dataset to minimize rework. However, doing so has consequences and should be avoided as discussed below.
Workspaces
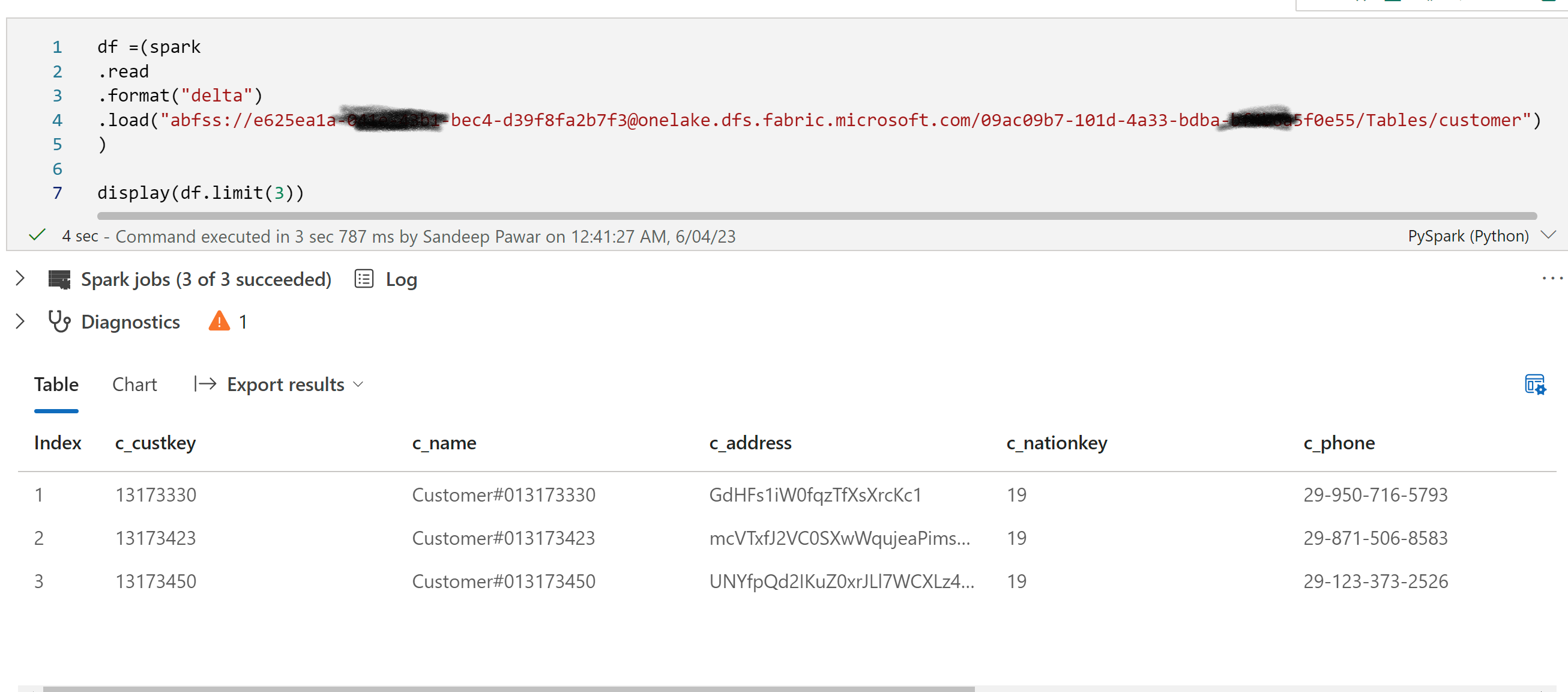
If you keep the spaces in workspace names, you will have to query the tables and files in spark notebook using the workspace id. As I mentioned in the previous blog, you do not need to mount a Lakeshouse to read or write using spark.
## query a table in a workspace with spaces in names
(spark
.read
.format("delta")
.load("abfss://<workspace_id>@onelake.dfs.fabric.microsoft.com/<lakehouse_id>/Tables/customer")
)
If the space is removed from the workspace name, i.e instead ofNew Opportunity Analysis we rename it to New_Opportunity_Analysis , we can use the lakehouse name and workspace name directly in the abfss path, instead of the GUIDs. This will make the code readable, and easier to track lineage when the notebook is shared or exported.
## with workspace and lakehouse names in the abfss path
(spark
.read
.format("delta")
.load("abfss://New_Opportunity_Analysis@onelake.dfs.fabric.microsoft.com/NewLakehouse.Lakehouse/Tables/customer")
)
Note that the abfss path is abfss://<workspace_name_without_spaces>@onelake.dfs.fabric.microsoft.com/<Lakehouse_name>.Lakehouse/Tables/customer . You have to add .Lakehouse after the Lakehouse name. For Datawarehouse items, add .Datawarehouse . This also works with URL paths and not just ABFSS paths.
The disadvantage here is that if the workspace name is changed in the future, it will break the code. Using GUID will always work. So it is up to the developer to assess what works best in their scenario. In most production cases, workspace names rarely change so I would default to using names instead of the GUIDs.
It's not possible to mix and match, i.e. use workspace GUID and Lakehouse name.
Thank you to Qixiao Wang at Microsoft for the information.
Just as a side note, if you run SELECT @@SERVERNAME on the T-SQL endpoint you will see that the server is actually the workspace GUID and Lakehouse is the database. So treat the workspace name as the server name and exclude the spaces.
Column Names
Delta tables by default do not allow special characters, including spaces, in column names. Let's take an example below, where the column names have spaces and are not business-friendly.

In a Power BI dataset, we would rename these columns by removing "_" and making them readable, e.g. instead of c_name we would use Customer Name etc. Let's do that and try saving it as a Delta table. To rename columns with Pyspark, we can use .withColumnRenamed() .
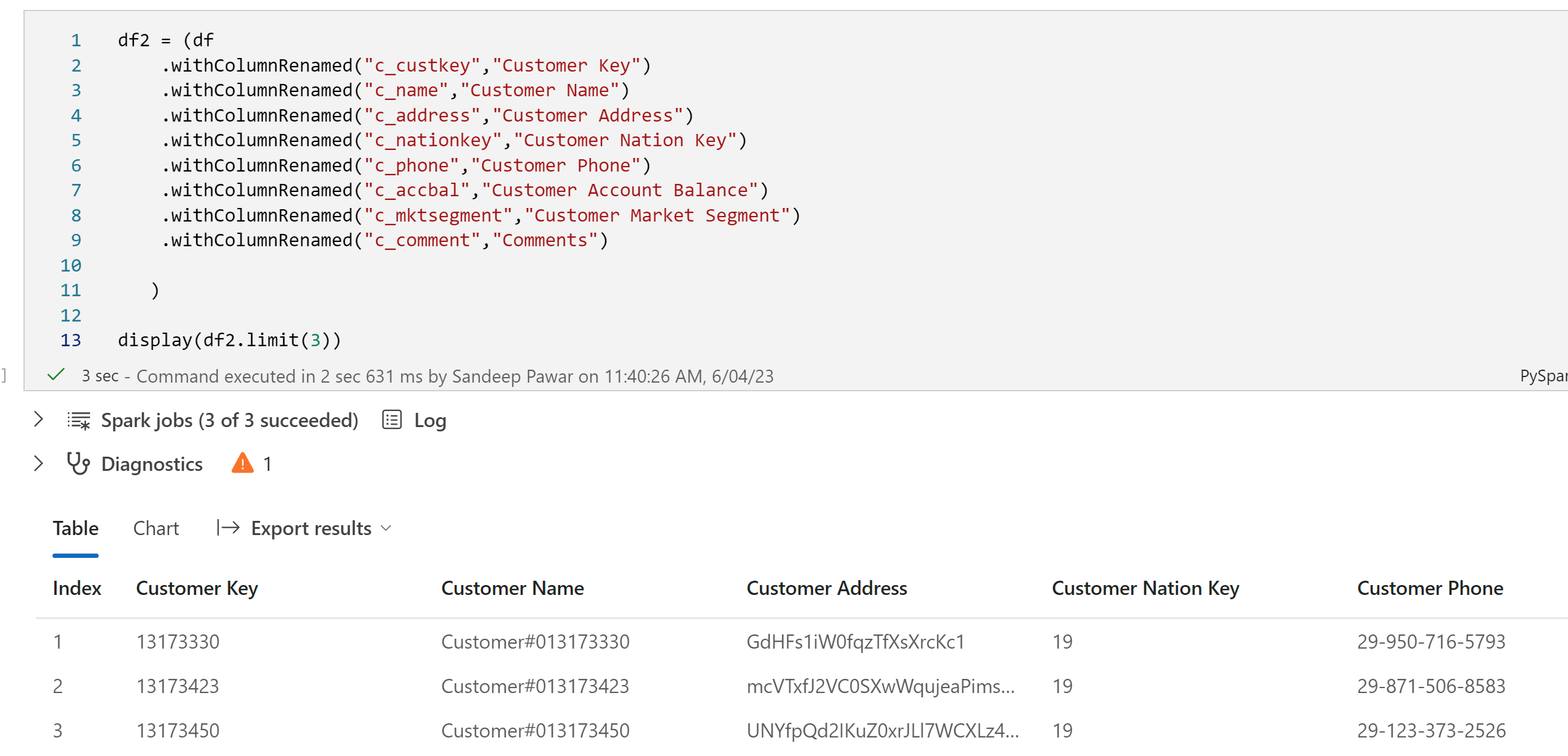
If I try to save this table with spaces in column names, I get the following error message, prompting me to set the column mapping config in spark settings.


Setting the Column Mapping to "name" worked successfully.option('delta.columnMapping.mode' , 'name')
(df2
.write
.format("delta")
.option('delta.columnMapping.mode' , 'name')
.saveAsTable("Customer_Table")
)
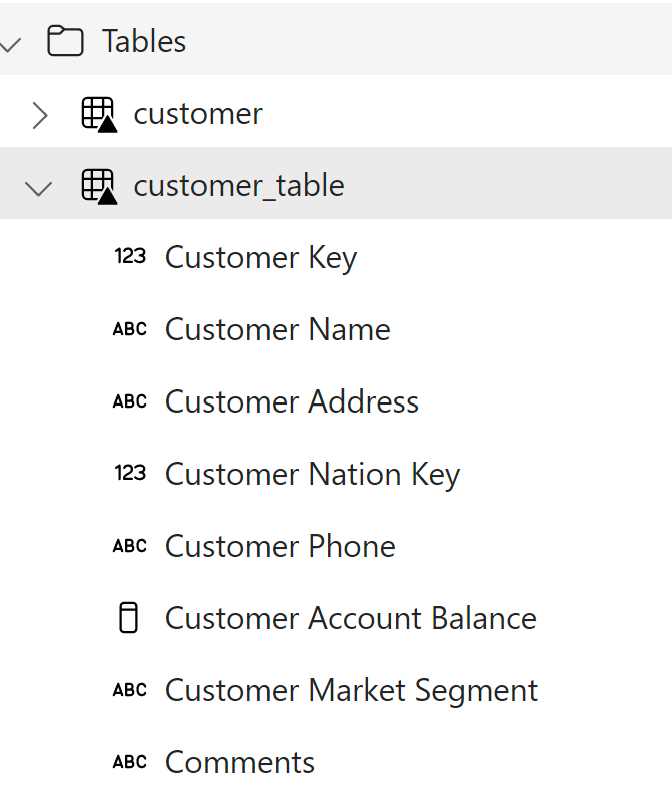
The new Delta table has column names that are business-friendly similar to Power BI datasets and have spaces in them.
However, there is a problem. If you switch over to the SQL Endpoint view, you will see an error message:

This is because, the SQL Endpoint does not support the column mapping property we defined earlier in spark, i.e. while Delta table supports the spaces, SQL Endpoint does not. This also means that when you try to create a dataset, this newly created table with column mapping won't even show up in the dialog box.

Hopefully, this limitation in Fabric will be removed in the future.
Upgrading protocols is an irreversible process, so be sure to test this on a test dataset before making any changes.
The solution, in my opinion, is instead to make column names lowercase and replace spaces with underscores instead. This will make it readable and also will be easier to change to title case with spaces in Tabular Editor later when XMLA-Write becomes available. It's common practice to keep names and variables lowercase in Python and Pyspark. Below C# can be used in the future to change column_name to Column Name for all tables when XMLA-W becomes available.
// Script to change column_name to Column Name
// Author : Sandeep Pawar | fabric.guru
// Loop through all the tables in the model
foreach (var table in Model.Tables)
{
// Loop through all columns in the table
foreach (var column in table.Columns)
{
// Replace spaces with underscore in all column names
string newName = column.Name.Replace("_", " ");
// Convert to title case
System.Globalization.CultureInfo cultureInfo = System.Threading.Thread.CurrentThread.CurrentCulture;
System.Globalization.TextInfo textInfo = cultureInfo.TextInfo;
newName = textInfo.ToTitleCase(newName);
// Update the column name
column.Name = newName;
}
}
To Recap: Clean the column names in the notebook or Dataflow Gen2 to lowercase with an underscore and then change it to title case without an underscore using Tabular Editor when XMLA Write becomes available. Note that you can rename manually as well in the web modeling experience. Avoid column mapping as it won't work with SQL Endpoint.
Update 6/19/2023: Charles Webb who is the Microsoft PM for DWH confirmed that column mapping is on the roadmap for Fabric.
Case Sensitivity of Column Names
Unlike Power BI, column names in spark dataframes are not case-sensitive. As you can see below, I have a dataframe with the same column names in different cases. This will not work in Power Query.

Spark environment does not provide a configuration setting to prevent the creation of dataframe columns with the same name but in different cases, even when case sensitivity is turned on using spark.conf.set("spark.sql.caseSensitive","true")
The case sensitivity setting only affects the way Spark SQL queries treat column names, it doesn't prevent you from creating a dataframe with columns whose names only differ by case.
Therefore, it's necessary to implement a manual check before or after creating the dataframe to ensure no two columns have the same name, disregarding case. Below function can be used to achieve that:
# function to check if schema contains duplicate column names (ignoring case)
def has_duplicates(schema):
column_names = [field.name.lower() for field in schema]
return len(column_names) != len(set(column_names))

Ideally, you will create Views to alias the column and table names but Direct Lake datasets cannot be created based on Views - yet.
What about Lakehouse and Table Names?
Both Lakehouse and Table names cannot contain spaces. Delta specification does not allow spaces in table names. Similar to the above approach, you can make the table names lowercase with an underscore for spaces and then update them in Tabular Editor later.
I should add that I am not 100% sure yet how to run the above C# scripts in pipelines to make it fully automated. If you have any thoughts, please let me know in the comments below.