Programmatically Creating, Managing Lakehouses in Fabric
Using mssparkutils to create, manage, update lakehouses in Microsoft Fabric
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
At MS Ignite, Microsoft unveiled a variety of new APIs designed for working with Fabric items, such as workspaces, Spark jobs, lakehouses, warehouses, ML items, and more. You can find detailed information about these APIs here. These APIs will be critical in the automation and CI/CD of Fabric workloads.
With the release of these APIs, a new method has been added to the mssparkutils library to simplify working with lakehouses. In this blog, I will explore the available options and provide examples. Please note that at the time of writing this blog, the information has not been published on the official documentation page, so keep an eye on the documentation for changes.
You can use the lakehouse REST API but I find it easier to use mssparkutils.
Lakehouse Method
To check all the available methods, use .help()
from notebookutils import mssparkutils
mssparkutils.lakehouse.help()
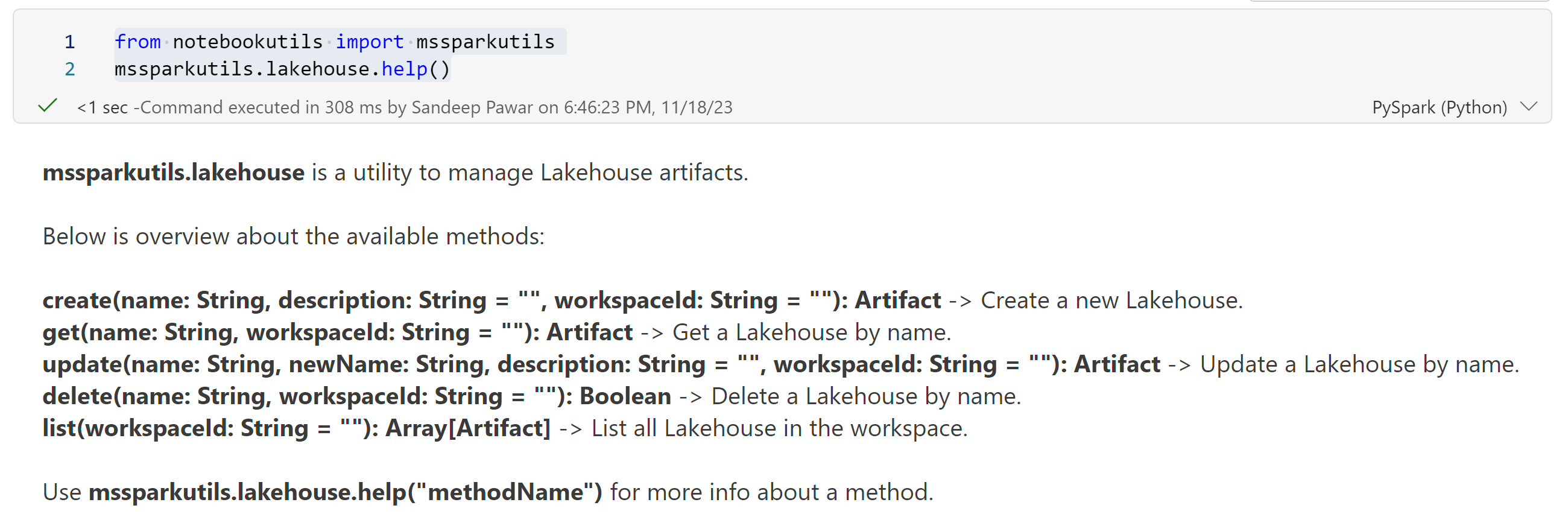
There are five methods create, get, update, delete and list. You can use mssparkutils.lakehouse.help("methodName") to get the description and the arguments.
create()
Use this to create a lakehouse in any of the Fabric workspaces.
create(name: String, description: String = "", workspaceId: String = "")
I created a test lakehouse as below. It created the lakehouse, SQL endpoint and a default semantic model. Note that it takes ~5-10 s for the SQL endpoint/lakehouse to get created so wait for ~10s before adding new items to this newly created lakehouse. Lakehouse names cannot have spaces or special characters like @,#,$,%. Underscores are allowed.


spark.conf.get("trident.workspace.id")get()
get() returns the details of the lakehouse. You can specify either the lakehouse name or the id. As mentioned above, excluding the workspace id will return the lakehouse of that name from the attached workspace.

update()
update() as the name suggests can be used to change the name or the description of the specified lakehouse. update does not change the lakehouse id, only the name and the description. newName is a required parameter.
list()
Use this to get a list of all the lakehouses in the specified workspace which is great.
Below I used the list method to get a list of all the lakehouses in all the workspaces the user has access to. Note that since these methods are calling APIs, the throttling limits are applicable. In the below code, I have added a 10s wait to overcome that, adjust as needed.
import requests
import pandas as pd
import time
from notebookutils.mssparkutils.credentials import getToken
from notebookutils.mssparkutils.lakehouse import list as list_lakehouse
def get_lakehouse_list():
"""
Sandeep Pawar | faric.guru
Retrieves a list of all lakehouses in all workspaces accessible to the user.
Only Fabric and Premium workspaces are used.
Refer https://learn.microsoft.com/en-us/rest/api/fabric/articles/throttling for throttling limits
Returns a pandas datafrema
"""
base_url = "https://api.powerbi.com/v1.0/myorg"
token = getToken("https://analysis.windows.net/powerbi/api")
headers = {"Authorization": f"Bearer {token}"}
response = requests.get(f"{base_url}/groups", headers=headers)
workspaces_data = response.json().get('value', [])
#Premium/Fabric only
premium_workspaces = pd.DataFrame(workspaces_data).query('isOnDedicatedCapacity == True')[["name", "id"]]
lakehouses = []
for ws_id in premium_workspaces['id'].unique():
lakehouses.append(pd.DataFrame(list_lakehouse(workspaceId=ws_id)))
time.sleep(10) # Throttling limit for compliance
return pd.concat(lakehouses, ignore_index=True)
# Call the function
lakehouse_data = get_lakehouse_list()
lakehouse_data
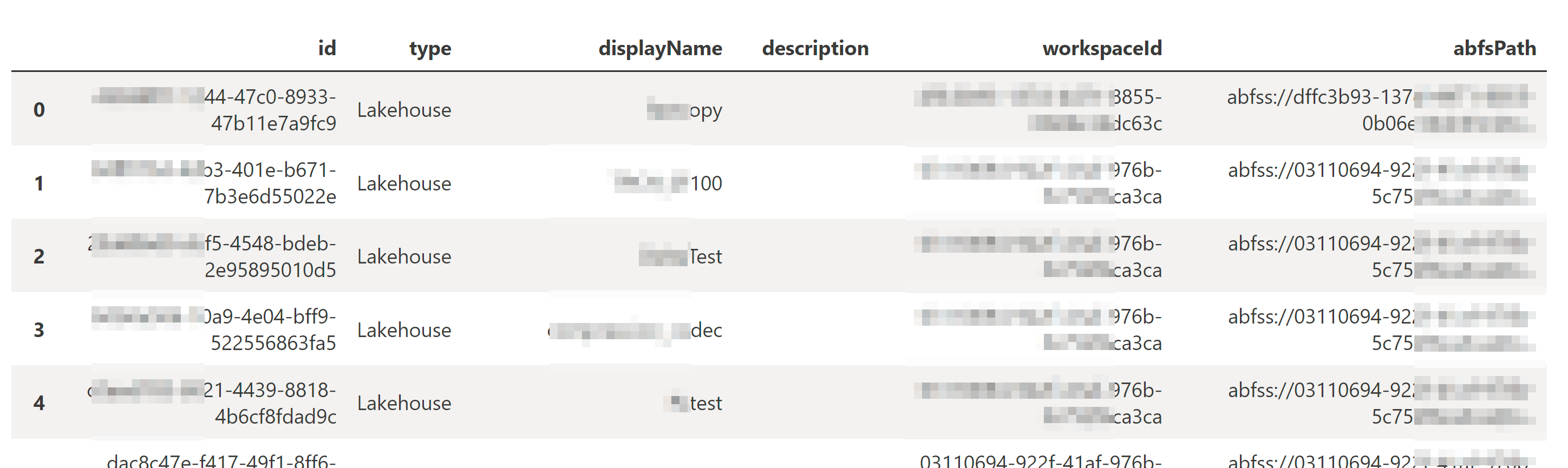
Using the Fabric REST API
Alternatively, you can use the Fabric REST API to get a list of all the lakehouses as below:
import requests
import pandas as pd
from requests.exceptions import HTTPError
def get_lakehouse_list_api():
'''
Sandeep Pawar | fabric.guru
This function uses the Fabric REST API to get all the lakehouses in the tenant that the user has access to.
'''
base_url = "https://api.fabric.microsoft.com/v1/admin/items?type=Lakehouse"
token = mssparkutils.credentials.getToken("https://api.fabric.microsoft.com/")
headers = {"Authorization": f"Bearer {token}"}
try:
response = requests.get(base_url, headers=headers)
response.raise_for_status()
data = response.json()
# Check if 'itemEntities' exists, may not exist for all items types
if 'itemEntities' not in data:
raise KeyError("'itemEntities' key not found in the response data")
lakehouses = pd.json_normalize(data['itemEntities'], sep='_')
return lakehouses
except HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
except Exception as err:
print(f"An error occurred: {err}")
get_lakehouse_list_api()
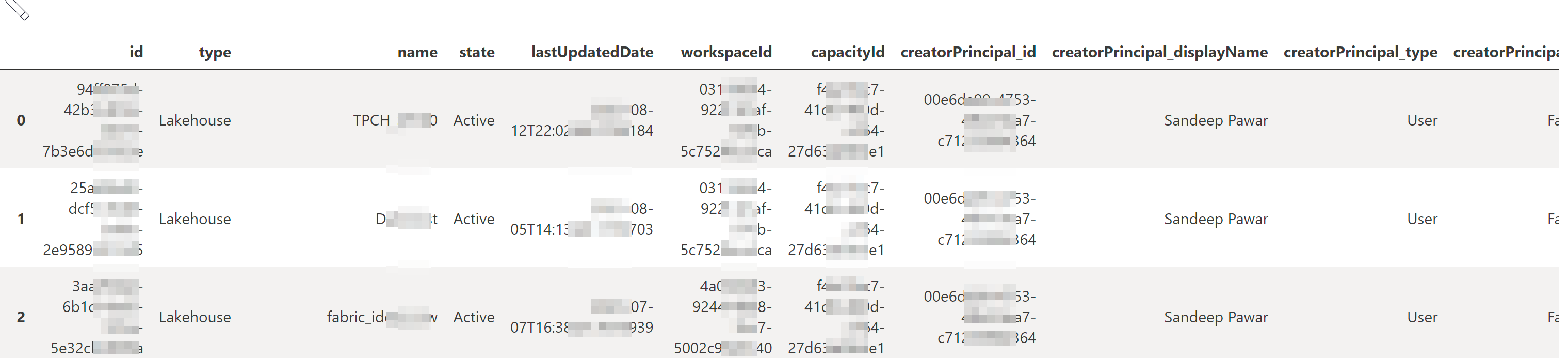
REST API returns a few additional details not provided by mssparkutils.
You may also find my other blog on mounting a lakehouse helpful. As a side note, to get the lakehouse attached to a notebook use:
spark.conf.get("trident.lakehouse.id")
spark.conf.get("trident.lakehouse.name")
Using Semantic-Link
Update Jan 12, 2024
With Semantic-Link v 0.5.0, you can use the create_lakehouse method to a create lakehouse in any workspace. By default, it will be created in the workspace attached to the notebook.
#install semantic link >= v0.5.0
!pip install --upgrade semantic-link --q
import sempy.fabric as fabric
from sempy.fabric.exceptions import FabricHTTPException
lh_name = "Sales_Lakehouse"
ws_name = None #if None use the default workspace else use the specified
try:
lh = fabric.create_lakehouse(display_name=lh_name, workspace=ws_name)
print(f"Lakehouse {lh_name} with ID {lh} successfully created")
except FabricHTTPException as exc:
print(f"An error occurred: {exc}")