I have written about V-order before. A quick summary from official MS Docs:
V-Order is a write time optimization for the parquet file format that enables fast reads under Microsoft Fabric compute engines like Power BI, SQL, Spark, and others. It improves data access times and provides cost efficiency and performance by applying sorting, row group distribution, dictionary encoding, and compression on parquet files.
To check if a table is V-order you can read my blog.
By default, all engines in Microsoft Fabric create V-order optimized tables. If they currently do not, they will be by GA. However, currently, there is one specific instance when tables will not be V-order'd - if you sort the dataframe in spark.
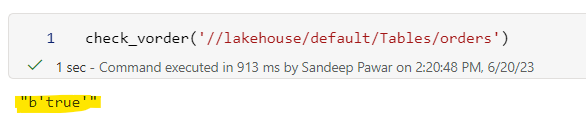
I have an existing table called orders . I can confirm if it's V-order'd by using my script from the above blog:
Sort & Save Table
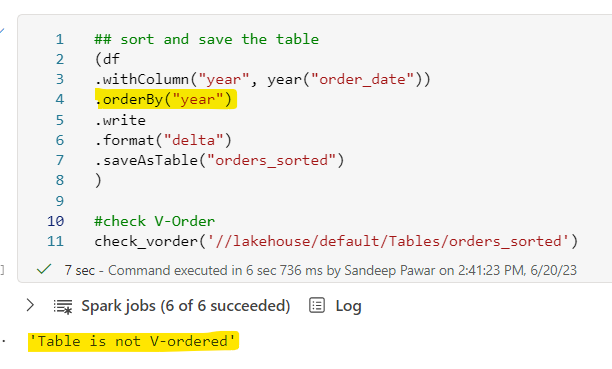
If I sort the spark dataframe and save the table, the table will not be V-order'd. User will not get any error or warning. In the example below, I sorted the dataframe by year column before saving and this resulted in a table without V-order.
Solution
To force V-order for a sorted dataframe, you have to use option("parquet.vorder.enabled", "force_true") while saving the table, as shown below.

You can also set spark configuration setting spark.conf.set('spark.sql.parquet.vorder.ignorePlan', 'true') to apply V-order in the Spark session.
As the product is in public preview, note that this behavior may change in the future. Always check if the table is V-order enabled. As far as I know, this is only applicable to spark. Refer to the official documentation here in the future for details.
Thank you to Tamas Polner at Microsoft for this information.