S
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
Search for a command to run...
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
No comments yet. Be the first to comment.
Last week Microsoft released an open-source text embedding model called Harrier in three sizes- 270M, 0.6B and 27B. I have been testing it in my RAG pipeline and so far it has crushed all my metrics.
For Power BI Copilot and Data agents with semantic models, you must use Prep Data for AI configuration to ground the responses in the context added in Prep for AI. In this blog, I will show you how yo
At FabCon Atlanta last week, the updated notebook Copilot for data engineering and data science was announced. It brings agentic capabilities to the Copilot and is much more intelligent and Fabric-awa
Using Fabric data agent Python SDK
Use workspace monitoring to monitor MCP server use
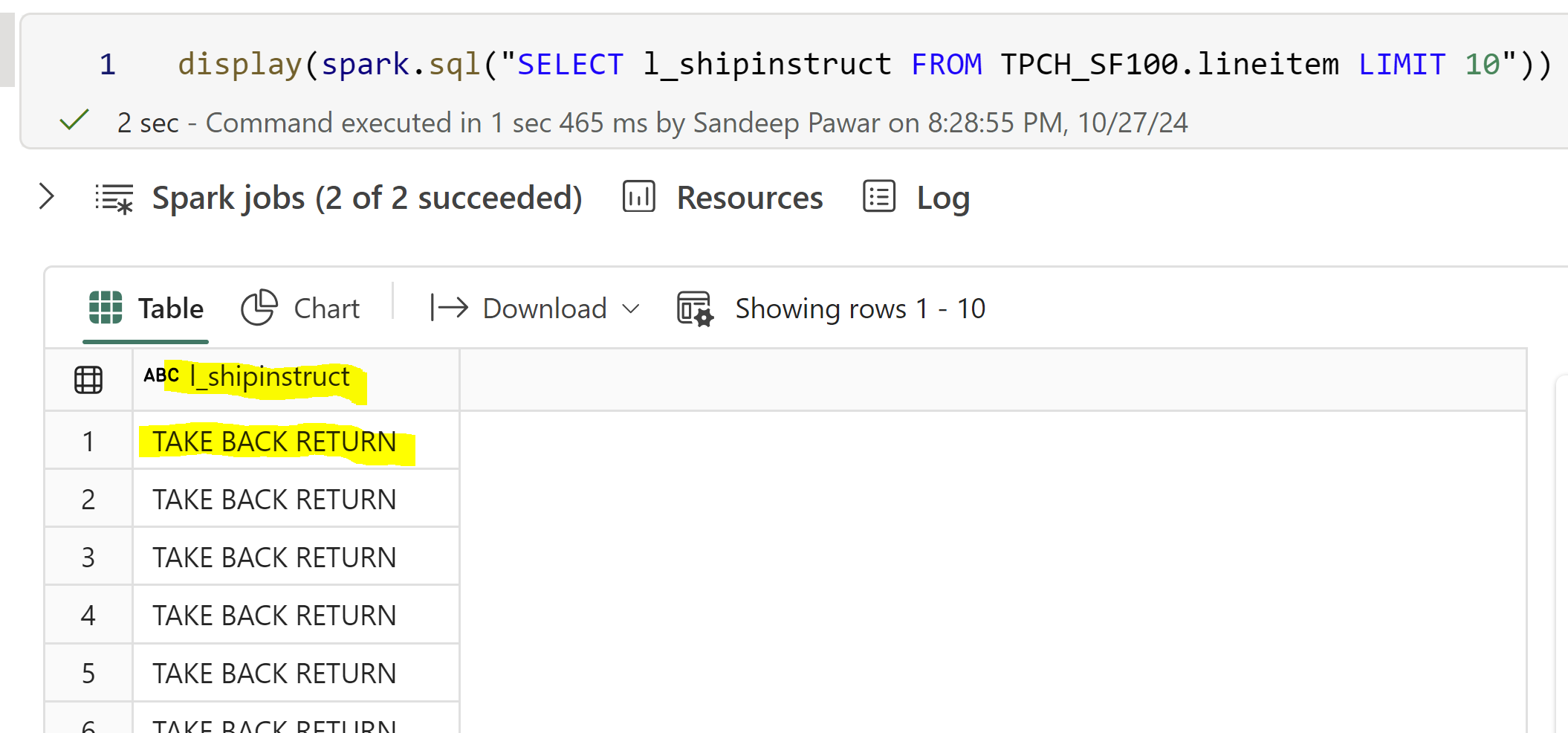
The answer is %pip. That’s what I have always done just based on experience and it’s explicitly mentioned in the documentation as well. But I wanted to experimentally verify myself. When you use !pip , it’s a shell command and always installs the library on the driver node only. %pip, on the other hand, is a magic command and installs the library on all driver and worker nodes. In Fabric, %pip has added functionality to the default %pip ipython magic command. Hence, when the job is processed by the executor nodes, the library is available for use. Let’s verify that !
In the below example, I am using lineitem table from TPC-H dataset with scale factor 100 so this table has 600M rows. When training an ML model with a training dataset containing categorical columns, you encode these columns to convert them into a numerical representation. One such handy library I have used is dirty-cat . (side note, I love this library for all the various methods available in one single package). I will install dirty-cat with !pip and %pip, encode l_shipinstruct column using a udf and show you exactly why %pip works and !pip doesn’t.
!pip install dirty-cat --q #first with !pip install
#%pip install dirty-cat --q #second with %pip install
from pyspark.sql.functions import udf, collect_list
from pyspark.sql.types import ArrayType, DoubleType, StringType
import numpy as np
from dirty_cat import SimilarityEncoder
import os
df = spark.sql("SELECT * FROM TPCH_SF100.lineitem")
# Define the encoding UDF
def create_dirty_cat_encoder_udf(df, input_col):
# get categorical values to encode
unique_values = df.select(input_col).distinct().toPandas()[input_col].tolist()
def encode_with_dirty_cat(value):
#fit & transfor the encoder
encoder = SimilarityEncoder(similarity='ngram')
encoder.fit(np.array(unique_values).reshape(-1, 1))
if value is None:
return [float(x) for x in np.zeros(len(unique_values))]
encoded = encoder.transform(np.array([value]).reshape(-1, 1))
return [float(x) for x in encoded[0]]
return udf(encode_with_dirty_cat, ArrayType(DoubleType()))
# Function to verify package installation
def get_package_info(package_name="dirty-cat"):
import pkg_resources
try:
package = pkg_resources.working_set.by_key[package_name]
return f"{package.key}=={package.version}"
except:
return "Not installed"
#VM ID using os.environ
def get_executor_id():
return os.environ.get('NM_HOST', 'unknown')
# Register verification UDFs
get_package_info_udf = udf(get_package_info, StringType())
executor_id_udf = udf(get_executor_id, StringType())
#Get each executor and verify if dirty-cat is installed
df.select(
executor_id_udf().alias("executor_id"),
get_package_info_udf().alias("dirty_cat_status")
).distinct().show(truncate=False)
#apply encoding
dirty_cat_encoder_udf = create_dirty_cat_encoder_udf(df, "l_shipinstruct")
encoded_df = df.withColumn(
"encoded_shipinstruct",
dirty_cat_encoder_udf("l_shipinstruct")
)
# result
encoded_df.select(
"l_shipinstruct",
"encoded_shipinstruct",
executor_id_udf().alias("processed_by_executor")
).show(truncate=False)
In the above code:
I created three UDFs:
To encode the categorical columns using dirty-cat
To check if the executor has dirty cat installed
To get the ID of the VM used for execution
I will first run with !pip, and then with %pip in a new session.
As expected, with !pip, the installation only took place on the driver and not on any of the executor nodes and the job failed.
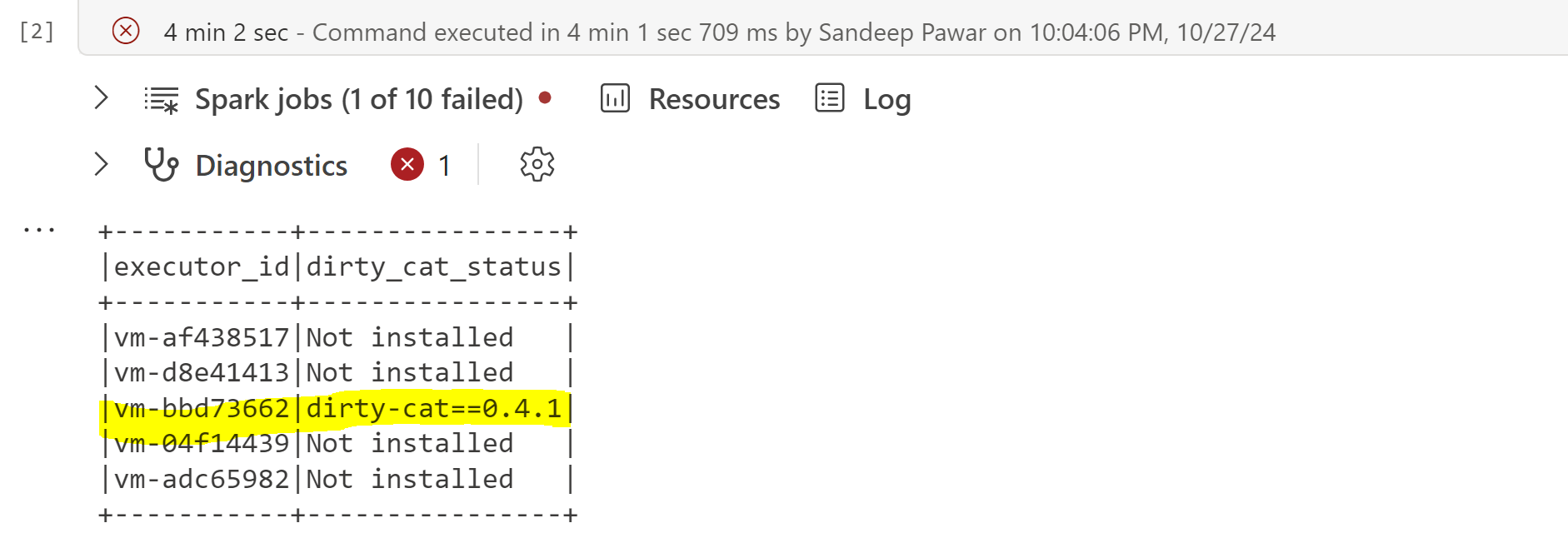

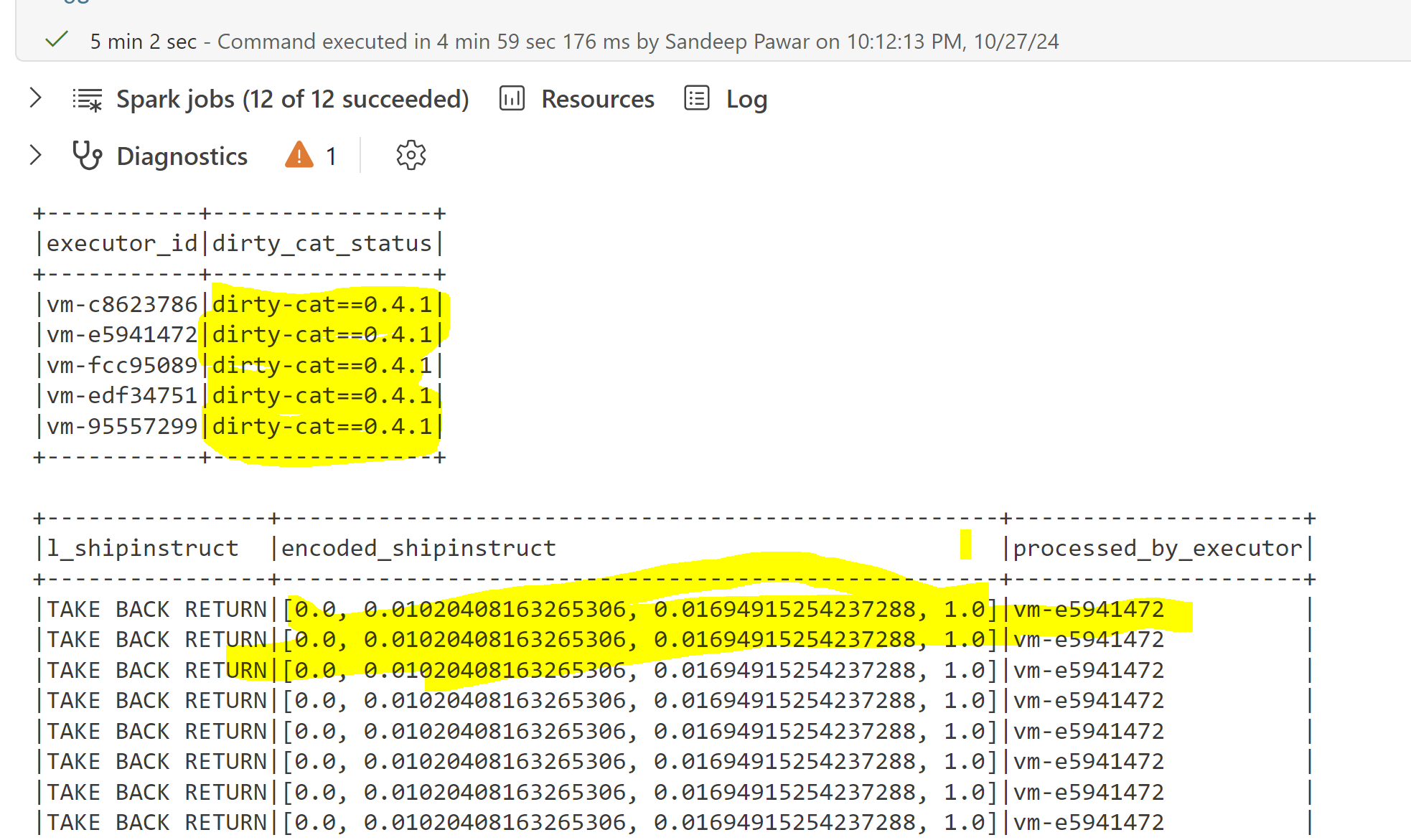
%pip installed the library on all nodes of the cluster and the job completed successfully.
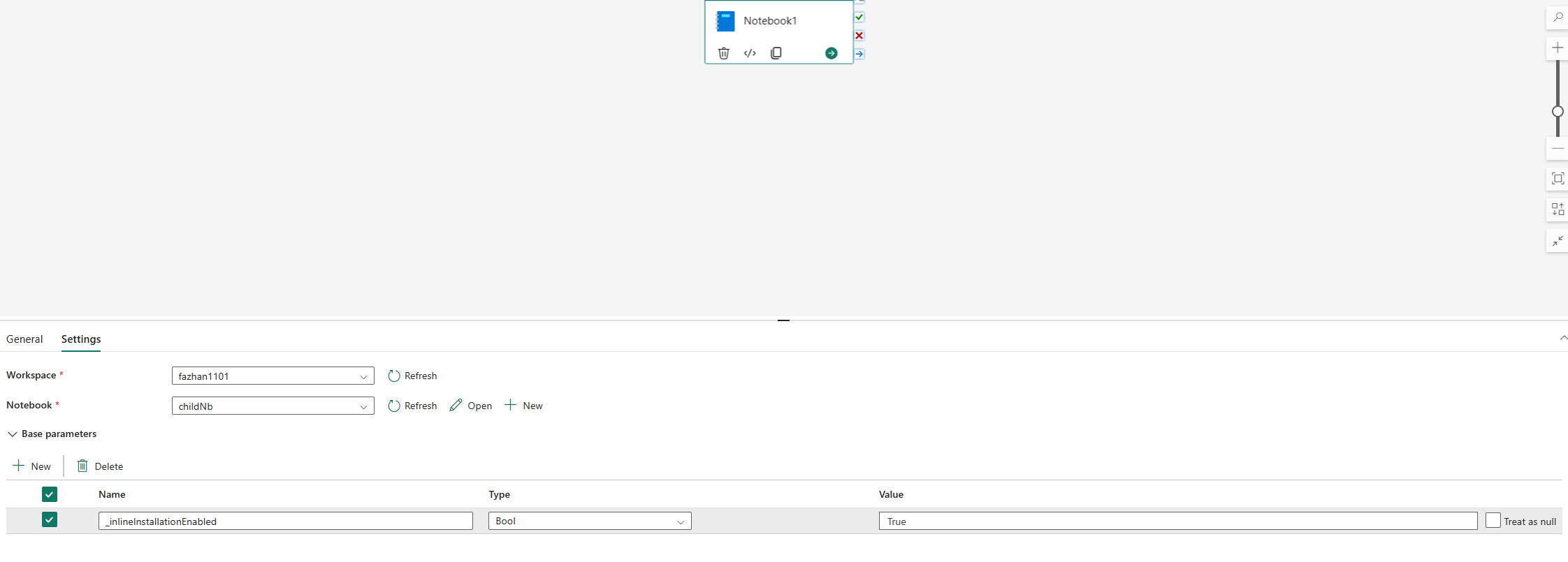
Another important reason why you should NOT use !pip is that it doesn’t work with notebooks executed in Fabric pipelines. You can use %pip with _inlineInstallationEnabled in notebook activity parameters.
Thanks to Renato Lira (Data Platform MVP) for pointing out that %pip is not supported in high concurrency session and instead you have to use !pip (I am not sure why, I am investigating). If you need to install libraries in HC mode, I recommend creating environments instead.
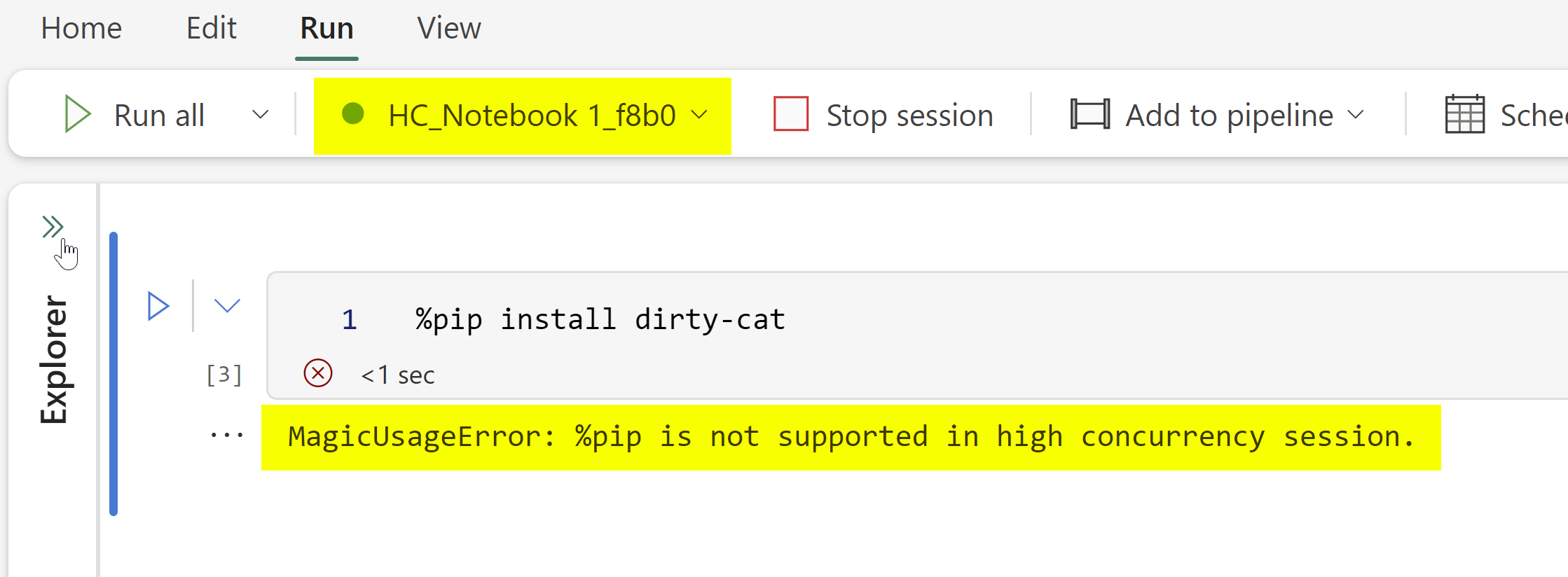
As expected, in HC mode using !pip threw an error:
This entire blog could have been just one sentence, but I was able to experimentally verify the installation on the spark cluster and see it for myself.
My friend Miles Cole used the Cat API in his recent Fabric spark blog . I am happy to continue the trend by using another cat related example in this spark post 🐱
At FabCon Europe, I asked the product team about custom live pools so users can reduce the start-up time ( $$$ ). While they don’t have anything on the roadmap for this, submit an idea if you have such a requirement.
When Python notebooks become available in Fabric, technically users should be able to use either !pip or %pip. But, even in that case, %pip is the right way installing because it will install in the base environment.
This was a contrived example to test and compare the two methods. In a real project, you would use UDFTransformer and fit it to the training set only in synapseml.