Since version 0.4 Semantic Link there have been several methods to refresh individual tables and partitions in a semantic model. In this blog, I will show how to use the .refresh_dataset().execute_tmsl() and TOM to achieve granular refresh.
Prerequisites: You need Microsoft Fabric capacity. The semantic model needs to be in a workspace backed by F/P/PPU capacity/license.
Method 1: Using the Enhanced Refresh API
To refresh the entire semantic model, use fabric.refresh_dataset( dataset, workspace ) . But you can also provide a list with key-value pairs for tables and partitions to refresh. This is particularly helpful for large semantic models and models with incremental refresh defined.
In the below example, I am only refreshing the Order_Details table and Customer-ROW partition from the Customers table.
You can use the REST API method as well, but this is a more convenient way in my opinion.
import sempy.fabric as fabric
dataset = "SL-Refresh"
workspace = "Sales"
objects_to_refresh = [
{
"table": "Customers",
"partition": "Customers-ROW"
},
{
"table": "Order_Details"
}
]
fabric.refresh_dataset(
workspace=workspace,
dataset=dataset,
objects=objects_to_refresh,
)
fabric.list_refresh_requests(dataset=dataset, workspace=workspace)

To confirm the partitions have been refreshed successfully, we can use the .get_tmsl() to get the details on each partition in the table.
import pandas as pd
import json
import sempy.fabric as fabric
def get_partition_refreshes(dataset, workspace):
"""
Sandeep Pawar | fabric.guru
Returns a pandas dataframe with three columns - table_name, partition_name, refreshedTime
"""
tmsl_data = json.loads(fabric.get_tmsl(dataset=dataset, workspace=workspace))
df = pd.json_normalize(
tmsl_data,
record_path=['model', 'tables', 'partitions'],
meta=[
['model', 'name'],
['model', 'tables', 'name']
],
errors='ignore',
record_prefix='partition_'
)
df = df.rename(columns={'model.tables.name': 'table_name'})
return df[['table_name', 'partition_name', 'partition_refreshedTime']]
df = get_partition_refreshes(dataset=dataset, workspace=workspace)
df
Sample output:

This method also has a ton of other options to refresh the semantic models in granular details and I highly recommend checking it out.
Update 4/15/2024: You can also use fabric.list_partitions() method to get the partition refresh timestamps.
Method 2: Using TMSL
Alternatively, you can use the .execute_tmsl to refresh specific tables and partitions. This is a far more flexible and powerful method because you can not only refresh the tables, you can alter the table/partition properties as well.
tmsl_script = {
"refresh": {
"type": "full",
"objects": [
{
"database": "SL-Refresh",
"table": "Order_Details"
},
{
"database": "SL-Refresh",
"table": "Customers",
"partition": "Customers-ROW"
}
]
}
}
fabric.execute_tmsl(workspace="<workspace_name>", script=tmsl_script)
With Semantic Link, you can define your own custom refresh schedules, make refreshes conditional (e.g. based on data quality checks, arrival of data etc.) and much more.
Method 3 : Using TOM (Semantic Link v>=0.7)
Update : Apr 15, 2024
With Semantic Link >=v0.7, you can update TOM properties. Below I show how you can update all/selected tables and all/selected partitions. I used this blog by Michael Kovalsky (Principal PM, Fabric CAT) as a reference.
Refreshing Selected Tables in a model
%pip install semantic-link --q
import sempy.fabric as fabric
from typing import List
def refresh_selected_tables(workspace_name:str, dataset_name:str, tables:List[str]=None, refresh_type:str="DataOnly"):
"""
Sandeep Pawar | Fabric.guru | Apr 12, 2024
Function to refresh selected tables from a semantic model based on a refresh policy
- Default refresh type is "DataOnly"
- If no table list is provided, all tables in the model are refreshed
Refer to blog by Michael Kovalsky for details : https://www.elegantbi.com/post/datarefreshintabulareditor
For Refresh types refer to #https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.refreshtype?view=analysisservices-dotnet
"""
ws = workspace_name or fabric.resolve_workspace_name(fabric.get_workspace_id())
all_tables = fabric.list_tables(dataset=dataset_name, workspace=ws)['Name']
selected_tables = all_tables if tables is None else tables
import Microsoft.AnalysisServices.Tabular as tom
tom_server = fabric.create_tom_server(False, ws)
tom_database = tom_server.Databases.GetByName(dataset_name)
if refresh_type == "DataOnly":
refreshtype = tom.RefreshType.DataOnly
elif refresh_type == "Full":
refreshtype = tom.RefreshType.Full
elif refresh_type == "Calculate":
refreshtype = tom.RefreshType.Calculate
elif refresh_type == "ClearValues":
refreshtype = tom.RefreshType.ClearValues
elif refresh_type == "Defragment":
refreshtype = tom.RefreshType.Defragment
else:
print("Enter valid refresh type, Valid values : DataOnly, Full, Calculate, ClearValues, Defragment")
try:
for table in selected_tables:
print("Refreshing : ",table)
tom_database.Model.Tables[table].RequestRefresh(refreshtype)
except Exception as e:
print("----Refresh Failed----")
print(f"An error occurred: {e}")
tom_database.Model.SaveChanges()
fabric.refresh_tom_cache(workspace=ws)
refresh_selected_tables(workspace_name="<workspace>", dataset_name="<dataset>")
Refreshing Selected Partitions in a model:
%pip install semantic-link --q
import sempy.fabric as fabric
import pandas as pd
from typing import Dict, List
def refresh_selected_partitions(workspace_name:str, dataset_name:str, partitions:Dict[str, List]=None, refresh_type:str="DataOnly"):
"""
Sandeep Pawar | Fabric.guru | Apr 12, 2024
Function to refresh selected partitions from a semantic model based on a refresh policy
- Default refresh type is "DataOnly"
- Partitions should be provided as a dictionary as below
partitions = {"tableA":["partition1","partition2"],"tableB":["partition4","partition6", "partition7"] }
Refer to blog by Michael Kovalsky for details : https://www.elegantbi.com/post/datarefreshintabulareditor
For Refresh types refer to #https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.refreshtype?view=analysisservices-dotnet
"""
ws = workspace_name or fabric.resolve_workspace_name(fabric.get_workspace_id())
all_partitions = fabric.list_partitions(dataset=dataset_name, workspace=ws)
if partitions:
partition_list = partitions
data_tuples = [(table, partition) for table, partitions in partition_list.items() for partition in partitions]
given_partitions = pd.DataFrame(data_tuples, columns=["Table Name", "Partition Name"])
selected_partitions = all_partitions if partitions is None else given_partitions
import Microsoft.AnalysisServices.Tabular as tom
tom_server = fabric.create_tom_server(False, ws)
tom_database = tom_server.Databases.GetByName(dataset_name)
if refresh_type == "DataOnly":
refreshtype = tom.RefreshType.DataOnly
elif refresh_type == "Full":
refreshtype = tom.RefreshType.Full
elif refresh_type == "Calculate":
refreshtype = tom.RefreshType.Calculate
elif refresh_type == "ClearValues":
refreshtype = tom.RefreshType.ClearValues
elif refresh_type == "Defragment":
refreshtype = tom.RefreshType.Defragment
else:
print("Enter valid refresh type, Valid values : DataOnly, Full, Calculate, ClearValues, Defragment")
try:
for idx, row in selected_partitions.iterrows():
table_name = row['Table Name']
partition_name = row['Partition Name']
print(f"Refreshing Partition: {partition_name} in Table: {table_name}")
tom_database.Model.Tables[table_name].Partitions[partition_name].RequestRefresh(refreshtype)
except Exception as e:
print("----Refresh Failed----")
print(f"An error occurred: {e}")
tom_database.Model.SaveChanges()
fabric.refresh_tom_cache(workspace=ws)
Note that there are five refresh type options : DataOnly, Full,Calculate, ClearValues, Defragment that you can specify.
For selectively refreshing partitions, provide the partitions as a dictionary as : partitions = {"table_nameA":["p1","p2"] , "table_nameA":["p3"]}
For conditional refreshing etc, use fabric.list_partitions(..) to check the last time a partition was refreshed and pass the dictionary to the above function for more granular, conditional refreshes
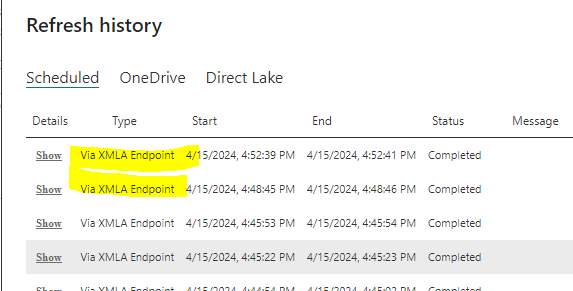
In refresh history, you will see the Type as "Via XMLA Endpoint"
- Michael also has a
refresh_semantic_model method in his library fabric_cat_tools . Check it out here.
Method 4 : Using PowerBIRestClient
Above methods work if the dataset you are refreshing is in a Premium/Fabric capacity. But you can use the PowerBIRestClient in Semantic Link to refresh a dataset in a Pro workspace. I have written about PowerBIRestClient before.
import sempy.fabric as fabric
client = fabric.PowerBIRestClient()
datasetId = "<dataset_id>"
client.post(f"/v1.0/myorg/datasets/{datasetId}/refreshes")
The limitation on number refreshes (8 per day) for Pro still apply.
Method 5 : Using Pipelines
As of Apr 15, 2024, you can also use the Fabric pipelines to refresh a semantic model as an activity in a pipeline. Currently, only the entire dataset can be refreshed and not the individual tables and partitions.

So which method should you use?
If you need to refresh the entire model, refresh semantic model activity is the easiest and cleanest option. You can use the pipeline activity to refresh a Pro dataset as well.
If you need to refresh individual tables and partitions, I like Option 1 using fabric.refresh_dataset because it's an API call so you are not making any structural changes to the model. Plus, since you will be using the notebooks, you can make it more dynamic and conditional. It uses the spark cluster though (until Python kernel becomes available) so I suspect, Web Activity will be a cheaper option (fewer CUs + avoids using spark vCores) if you know which tables/partitions to refresh and the logic is straightforward.