First, if you haven't noticed mssparkutils has been officially renamed to notebookutils. Check out the official documentation for details. Be sure to use/update your notebooks to notebookutils.
I have written about runMultiple before. It allows you to run multiple notebooks in parallel with a defined orchestration pattern including dependencies. notebookutils now also has .validateDAG method to check if the DAG has been defined per the expected JSON structure. It can be helpful check before executing runMultiple.
Example:
I will use the same DAG I used in my previous blog.
DAG = {
"activities": [
{
"name": "extract_customers",
"path": "extract_customers",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 1000},
},
{
"name": "extract_products",
"path": "extract_products",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 5000},
},
{
"name": "extract_offers",
"path": "extract_offers",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 1000},
},
{
"name": "extract_leads",
"path": "extract_leads",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 100000},
},
{
"name": "customer_table",
"path": "customer_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_customers"]
},
{
"name": "products_table",
"path": "products_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_products"]
},
{
"name": "leads_table",
"path": "leads_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_leads","customer_table", "products_table"]
},
{
"name": "offers_table",
"path": "offers_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_offers","customer_table", "products_table"]
},
{
"name": "refresh_dataset",
"path": "refresh_dataset",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["customer_table","products_table","leads_table","offers_table"]
}
],
"timeoutInSeconds": 3600, # max 1 hour for the entire pipeline
"concurrency": 5 # max 5 notebooks in parallel
}
notebookutils.notebook.validateDAG(DAG)
#Output True
If I add a dependency that doesn't exist, validation will fail.
INVALID_DAG = {
"activities": [
{
"name": "extract_customers",
"path": "extract_customers",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 1000},
},
{
"name": "extract_products",
"path": "extract_products",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 5000},
},
{
"name": "extract_offers",
"path": "extract_offers",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 1000},
},
{
"name": "extract_leads",
"path": "extract_leads",
"timeoutPerCellInSeconds": 120,
"args": {"rows": 100000},
},
{
"name": "customer_table",
"path": "customer_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["THIS_NOTEBOOK_DOES_NOT_EXIST"] ###INVALID
},
{
"name": "products_table",
"path": "products_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_products"]
},
{
"name": "leads_table",
"path": "leads_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_leads","customer_table", "products_table"]
},
{
"name": "offers_table",
"path": "offers_table",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["extract_offers","customer_table", "products_table"]
},
{
"name": "refresh_dataset",
"path": "refresh_dataset",
"timeoutPerCellInSeconds": 90,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["customer_table","products_table","leads_table","offers_table"]
}
],
"timeoutInSeconds": 3600, # max 1 hour for the entire pipeline
"concurrency": 5 # max 5 notebooks in parallel
}
notebookutils.notebook.validateDAG(INVALID_DAG)
#Returns error
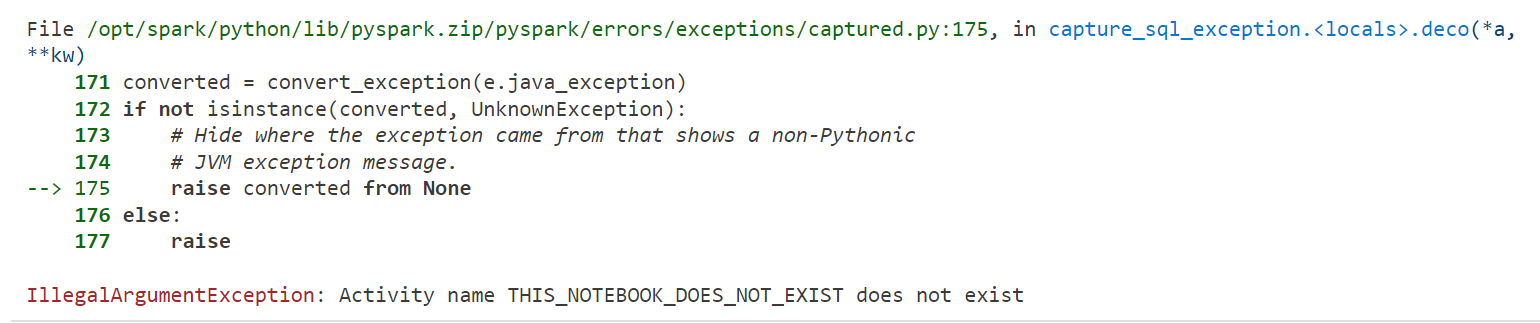
Note that validation is not exhaustive. For example, you could enter concurrency as -5 which is invalid as it has to be a positive number but validateDAG will not flag it as an error. But this is still very handy.