Loading ML Models in Fabric Data Science
Loading a registered model for scoring
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
This will be a short blog post. One of my colleagues was going through the Fabric Data Science documentation and did not find anything on how to get the model URI. If you are coming from Databricks, you can get the URI directly from the MLFlow model registry. The model hub in Fabric doesn't (yet) show that in the UI nor does it mention it anywhere in the documentation.
If you follow the documentation, you will see that the model is loaded using MLflowTransformer API from SynapseML as below:
from synapse.ml.predict import MLflowTransformer
spark.conf.set("spark.synapse.ml.predict.enabled", "true")
model = (MLFlowTransformer( inputCols=["x"],
outputCol="prediction",
modelName="sample-sklearn",
modelVersion=1, ))
SynapseML performs model scoring in parallel using the spark cluster. But what if you have existing code or don't want to use SynapseML? The solution is easy, you use the MLFlow API.
I will first get a list of all the registered models.
## This is optional, I am just getting a list of all the models
import mlflow
import pandas as pd
from mlflow import MlflowClient
## Instantiate the MLFlow client
client = MlflowClient()
#Get a list of models in the workspace
models_list = client.search_registered_models()
models_dict_list = [dict(model) for model in models_list]
# Return a dataframe showing the models
models_df = pd.DataFrame(models_dict_list)
models_df
The above code will return a list of models registered in the worskpace.

If you already know the model and the version you want to use, you can directly use that for scoring as:
For sklearn:
For a specific version of the model:
model = mlflow.sklearn.load_model(model_uri="models:/<model_name>/<version>")
For the latest version of the model:
model = mlflow.sklearn.load_model(model_uri="models:/<model_name>/latest")
Custom Flavor Model:
If you are not using any specific model flavor such as sklearn, pytorch etc., you can use:
model = mlflow.pyfunc.load_model(model_uri="models:/<model_name>/<model_version>")

Spark UDF:
You can also load the model as a spark UDF to parallelize scoring on a spark dataframe. You have to specify the conda environment which will recreate the environment at the time of inferencing.
mlflow.pyfunc.spark_udf(spark,model_uri="models:/<model_name>/latest",env_manager="conda")
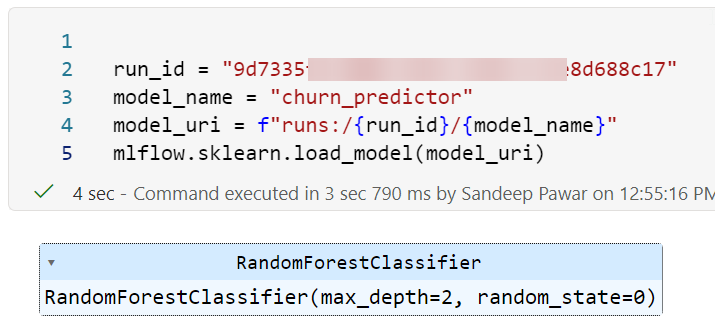
Using run id:
You can also use the experiment run id to obtain the model URI and load a model from a specific experiment:
model_uri = f"runs:/{run_id}/{model_name}"
Example:
I know, it was too easy but hopefully, I saved you some time until the documentation improves.
Note here that the model URI doesn't have any reference to a workspace. That's because, currently, cross-workspace model URIs aren't available. You can only use the model in the workspace it resides in. This will change in the future. For now, as a workaround, you could save the serialized model to the lakehouse and load it. The drawback of this approach is that it bypasses the model registry, which deviates from best practices.
Stay tuned, I have a whole series of blogs planned for Data Science and ML on Fabric!