Fabric : Not All Delta Tables Are Created Equally
It matters which engine is used to create the Delta table, especially for optimal Direct Lake performance.
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
Tables in a Microsoft Fabric lakehouse are based on the Delta Lake table format. Delta Lake is an open-source storage layer for Spark that enables relational database capabilities for batch and streaming data. By using Delta Lake, you can implement a lakehouse architecture to support SQL-based data manipulation semantics. All compute engines in Fabric create Delta tables which can be used for analytics. Depending on the skill and experience level of the person using Fabric, they can choose the compute engine they are most familiar with and create the Delta tables. The size, number of files, number of rowgroups, and number of rows per rowgroup play an important role in analytical workload performance. Ideally, all compute engines should create optimized Delta tables that are same/similar. But do they and how does it impact performance?
Setup
I used the Fabric F64 trial capacity with the standard medium node. I used the lineitem table from the TPCH_SF100. This table has 600 million rows and 15 columns. I saved it in the Files section as parquet files, ~19.4 GB in size. To test whether each compute creates same/similar Delta tables, I used the same source data (i.e parquet files) and created the Delta tables as below:
DFg2 : Dataflow Gen 2 with Lakehouse as the destination
PL: Using copy activity in Data Factory
DWH : Datawarehouse
spark: In Fabric, by default optimize Write spark configuration aims to optimize the number of files and file size. I created Delta using three configurations:
spark_optimizeon : pysaprk with
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")spark_optimizeoff : pysaprk with
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "false")spark_optimize : OPTIMIZE to reduce the number of files with fewer large files.
Load To Tables : Not available yet for folders so couldn't test
It is important to mention here that Fabric is still in Public Preview and under development. I have been running tests and measuring performance in Fabric since its launch and wanted to understand if it matters which engine was used for creating Delta lake. These results will change based on your data, configurations and updates made to these engines. Run your own tests and experiments to draw conclusions.
Here is the schema of this table:

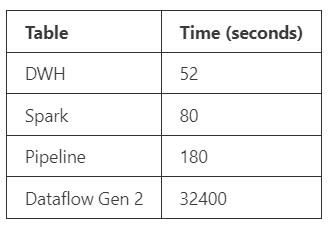
Delta Write Time:
Below is how long it took for each method. Dataflow Gen2 took 9 hours to ingest and save to the lakehouse! No surprise, we know Dataflow Gen2 is still being developed actively and hopefully it will be as fast as DWH and spark by GA. This will be especially critical for Power BI developers.
Delta Structure
To analyze the Delta tables, I looked at :
size of the Delta table
number of parquet files
average file size
if the Delta was V-Order optimized
number of rowgroups and number of rows per rowgroup (For this I looked at the largest parquet file in the table)
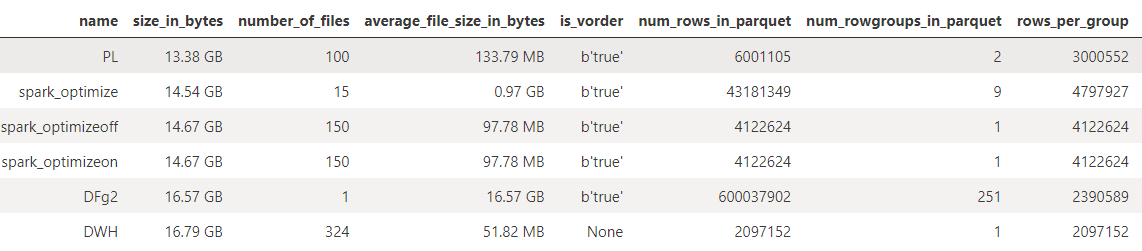
Below are the results:
Observations:
It is evident from the results above, not all Delta tables are created equally
Pipeline created the smallest Delta table (13.4GB) and DWH/DFg2 the largest (16.8GB). All spark configurations created about the same Delta size.
The number of parquet files varies significantly. The number of files in a Delta table directly affects the performance of compute operations. Having a large number of small files can lead to increased overhead during read operations due to the need to open multiple file connections while having too few large files can limit parallelism and result in data skew during processing. Ideally, all engines should create same/similar number of files. But, Dataflow Gen2 created a single monster parquet file that's 16.6 GB in size while DWH created many small files with an average file size of 52 MB.
What's interesting is that I expected optimizeWrite to automatically optimize the number of files and file size but it did not. This spark configuration did not affect the Delta size/structure. It's possible that spark engine already optimized the Delta and there is not much room for further optimization. Hence, I ran another test with OPTIMIZE command.
Running
OPTIMIZEreduced the number of files from 150 to 15 with each file being ~1GB in size.The number of row groups in a Delta table is essential as it affects query performance: too many can increase management overhead, while too few or overly large ones can limit query optimization and cause unnecessary data reading. Balancing the size and number of row groups based on your data and queries is crucial for optimal performance. There is no magic number for the number of rowgroups or the size of the rowgroups. It depends on the engine and the operation. In this case, both vary significantly based on the engine used. We can expect the performance to vary as well. For my purposes, I will focus on Direct Lake and spark query performance.
Query Performance
I ran a simple aggregation query based on two low cardinality columns and aggregated two numeric columns in spark and Direct Lake.
durations = []
for t in list(final.name):
start_time = time.time()
df = (spark
.read
.format("delta")
.load("Tables/"+t)
.groupby(["l_returnflag","l_linestatus"])
.sum("l_quantity","l_extendedprice")
.collect()
)
duration = time.time()-start_time
durations.append(math.ceil(duration))
print(t,duration )
final["spark_duration"] = durations
final
The lowest durations are highlighted in yellow in the table below. For Direct Lake, all DAX query runtimes are cold cache, meaning after each run I reframed the dataset manually to ensure it's hitting the cold cache.

Observations:
Dataflow Gen2 was the slowest for spark and Direct Lake. This was expected as DFg2 created one giant parquet file.
Except for DFg2, spark performance wasn't affected much for this query
DWH currently doesn't support Direct Lake and hence it was in Direct Query mode (47s). But this gives a good way to benchmark Direct Lake performance.
All spark created tables ran faster than Direct Query. Delta table created with
OPTIMIZEran the fastest, even faster than the other two spark tables. I am not sure if my tests are wrong, data is not conducive for optimizeWrite or optimizeWrite isn't working as expected.Delta size and structure matter for Direct Lake performance. I don't know what and how to optimize but that's what oprimizeWrite was supposed to provide. More tests on diverse datasets will be needed to understand the implications of Delta table structure on Direct Lake performance.
Definitely pay extra attention to Delta tables created with DFg2 while it is still in development.
I should mention that I also compared warm cache performance and as expected there was no difference in performance. After caching the data in memory, the same queries returned the data in ~300ms, giving import-like performance.
Note that all the Delta tables were V-Order optimized (except for DWH which doesn't show V-order in the logs).
Conclusion & Thoughts
I hate to generalize based on a limited set of tests and especially while Fabric is still in development but for my dataset, the queries I ran and the configurations I considered, spark created Delta tables were most optimal for Direct Lake performance. Optimize the Delta tables with OPTIMIZE and do not rely on optimizeWrite alone at this point. Avoid Dataflow Gen2 for performance comparisons, while it is still in development. Certainly test, experiment with DFg2 but be aware that Delta tables may not be optimal. While spark query performance is not affected much by the underlying Delta table, Direct Lake performance is certainly influenced by it. Not all Delta tables are created equally in Fabric.
I will run these tests again every few weeks to check how Fabric changes and improves. Let me know your thoughts, and any additional tests/configurations I should consider.