Controlling Direct Lake Fallback Behavior
Changing the Direct Lake fallback for reliability and performance
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.
In the flurry of announcements at MS Ignite, one significant feature related to Direct Lake got buried. You can now control the fallback behavior of the Direct Lake semantic model. Before we get into how you do that, a quick recap of what is fallback.
What is fallback?
When you create a Direct Lake semantic model, by default it is in Direct Lake mode, i.e. you will directly query the delta table from the lakehouse/warehouse. This is what we want because the query performance will be very much comparable to the import mode. However, under certain circumstances, the DAX query can fallback to DirectQuery if Direct Lake limitations are reached. This was one of the major limitations of Direct Lake because:
While in some cases DirectQuery can be faster on the first read, subsequent performance will be significantly slower
DirectQuery has its own limitations
This fallback behavior is highly dynamic and relies on a number of factors. When developing the model, you must test the queries using DAX Studio or Performance Analyzer to determine whether the query is in Direct Lake or DirectQuery mode. Chris Webb has a series of blogs that cover this in great detail. Even if the query is in DirectLake when you tested it during development, there is no guarantee that it will always be in Direct Lake in service.
If the users experience slow report performance, it will be hard to debug and reproduce given the dynamic nature of the fallback mechanism.
Currently, if you create a semantic model using the delta tables in the web modeling, the table storage mode will show "Direct Lake" despite the fact that the DAX queries could be in DirectQuery (that's because while the storage mode of the partition is Direct Lake, the DAX queries could be DL or DQ). This adds to the confusion.

I should note that fallback doesn't mean, the report will stop working. In case of fallback, the query will switch from Direct Lake to DirectQuery and thus the report performance will be slower than expected.
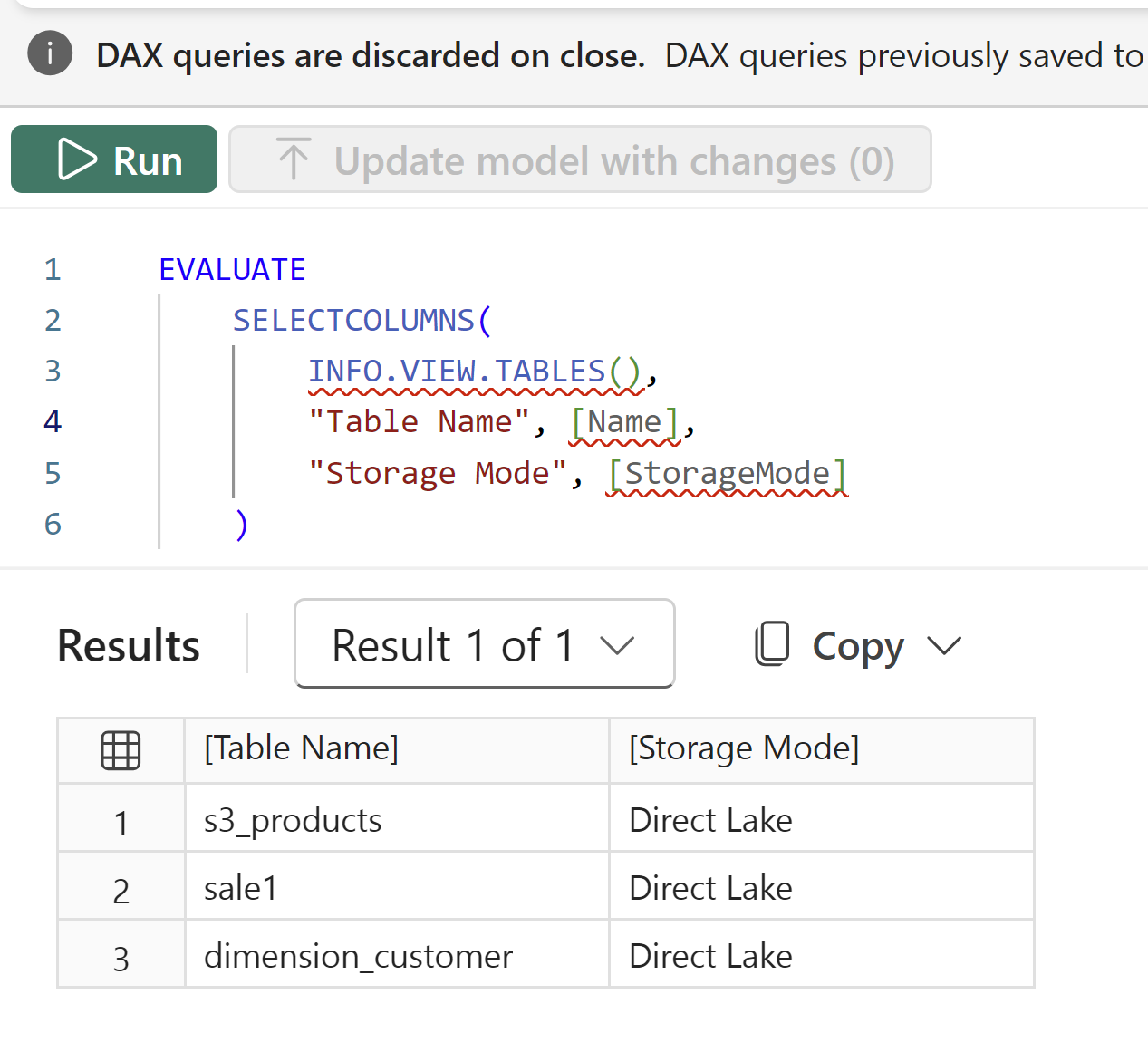
INFO.VIEW.TABLES() can be used to identify the storage mode of the table. Note that, as discussed below, it does not mean the queries will be in Direct Lake mode.EVALUATE
SELECTCOLUMNS(
INFO.VIEW.TABLES(),
"Table Name", [Name],
"Storage Mode", [StorageMode]
)
When does fallback occur?
Below are some of the scenarios when fallback can occur:
The number of files per table, row groups per table, number of rows per table, model size on disk are reached
💡If the semantic model size exceeds Max memory limit shown below, it will cause the model to be evicted (i.e. paged out) and not fallback. If the model is paged out of memory, it will lead to performance degradation for large models.
Semantic model uses data warehouse views
If the model size on disk exceeds the max size per SKU, the model (not the query) will fall back to DQ
RLS/OLS are defined in the data warehouse
Semantic model is published via XMLA endpoint and has not been reframed.
This is not a fallback criteria rather a known issue/limitation. If you create a Direct Lake model and it is unprocessed, it will fall back to Direct Query. You can read about it here in the official docs. I explained this in the video below:
Always refer to the official documentation for details.
How to control fallback?
If you stay within the above limitations, the semantic model should operate in Direct Lake mode. If your model size is small based on the P/F SKU and if you perform delta table maintenance frequently (read this excellent blog by my colleague Miles Cole), you can avoid fallback.
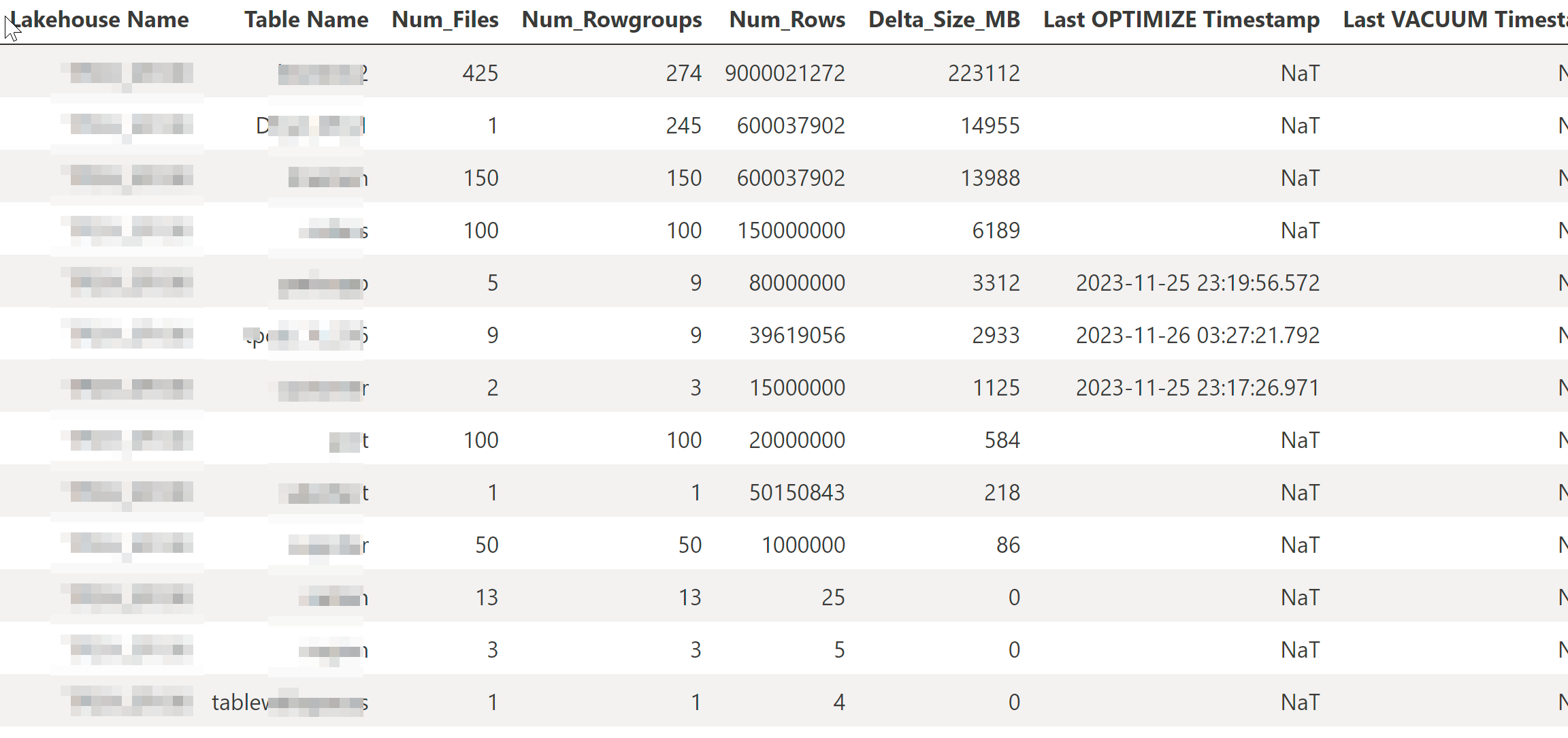
You can use below Python script to get number rows, rowgroups, number of files, for the default lakehouse mounted in the notebook. Compare these numbers with the limits from the above table based on your SKU. Note that the Delta_Size_MB in the table below is the size of the Delta table and not the semantic model size. I have included it as a reference. To get the size of the model in memory, use Vertipaq Analyzer.
import pandas as pd
import pyarrow.parquet as pq
import numpy as np
def gather_table_details():
"""
Sandeep Pawar | fabric.guru | Nov 25, 2023
Collects details of Delta tables including number of files, rowgroups, rows, size, and last OPTIMIZE and VACUUM timestamps.
This can be used to optimize Direct Lake performance and perform maintenance operations to avoid fallback.
The default Lakehouse mounted in the notebook is used as the database.
Returns:
DataFrame containing the details of each table, or a message indicating no lakehouse is mounted.
"""
# Check if a lakehouse is mounted
lakehouse_name = spark.conf.get("trident.lakehouse.name")
if lakehouse_name == "<no-lakehouse-specified>":
return "Add a lakehouse"
def table_details(table_name):
detail_df = spark.sql(f"DESCRIBE DETAIL `{table_name}`").collect()[0]
num_files = detail_df.numFiles
size_in_bytes = detail_df.sizeInBytes
size_in_mb = size_in_bytes / (1024 * 1024)
# Optional, set to False to avoid counting rows as it can be expensive
countrows = True
num_rows = spark.table(table_name).count() if countrows else "Skipped"
delta_table_path = f"Tables/{table_name}"
latest_files = spark.read.format("delta").load(delta_table_path).inputFiles()
file_paths = [f.split("/")[-1] for f in latest_files]
# Handle FileNotFoundError
num_rowgroups = 0
for filename in file_paths:
try:
num_rowgroups += pq.ParquetFile(f"/lakehouse/default/{delta_table_path}/{filename}").num_row_groups
except FileNotFoundError:
continue
history_df = spark.sql(f"DESCRIBE HISTORY `{table_name}`")
optimize_history = history_df.filter(history_df.operation == 'OPTIMIZE').select('timestamp').collect()
last_optimize = optimize_history[0].timestamp if optimize_history else None
vacuum_history = history_df.filter(history_df.operation == 'VACUUM').select('timestamp').collect()
last_vacuum = vacuum_history[0].timestamp if vacuum_history else None
return lakehouse_name, table_name, num_files, num_rowgroups, num_rows, int(round(size_in_mb, 0)), last_optimize, last_vacuum
tables = spark.catalog.listTables()
table_list = [table.name for table in tables]
details = [table_details(t) for t in table_list]
details_df = pd.DataFrame(details, columns=['Lakehouse Name', 'Table Name', 'Num_Files', 'Num_Rowgroups', 'Num_Rows', 'Delta_Size_MB', 'Last OPTIMIZE Timestamp', 'Last VACUUM Timestamp'])
return details_df.sort_values("Delta_Size_MB", ascending=False).reset_index(drop=True)
details_df = gather_table_details()
details_df
Output:
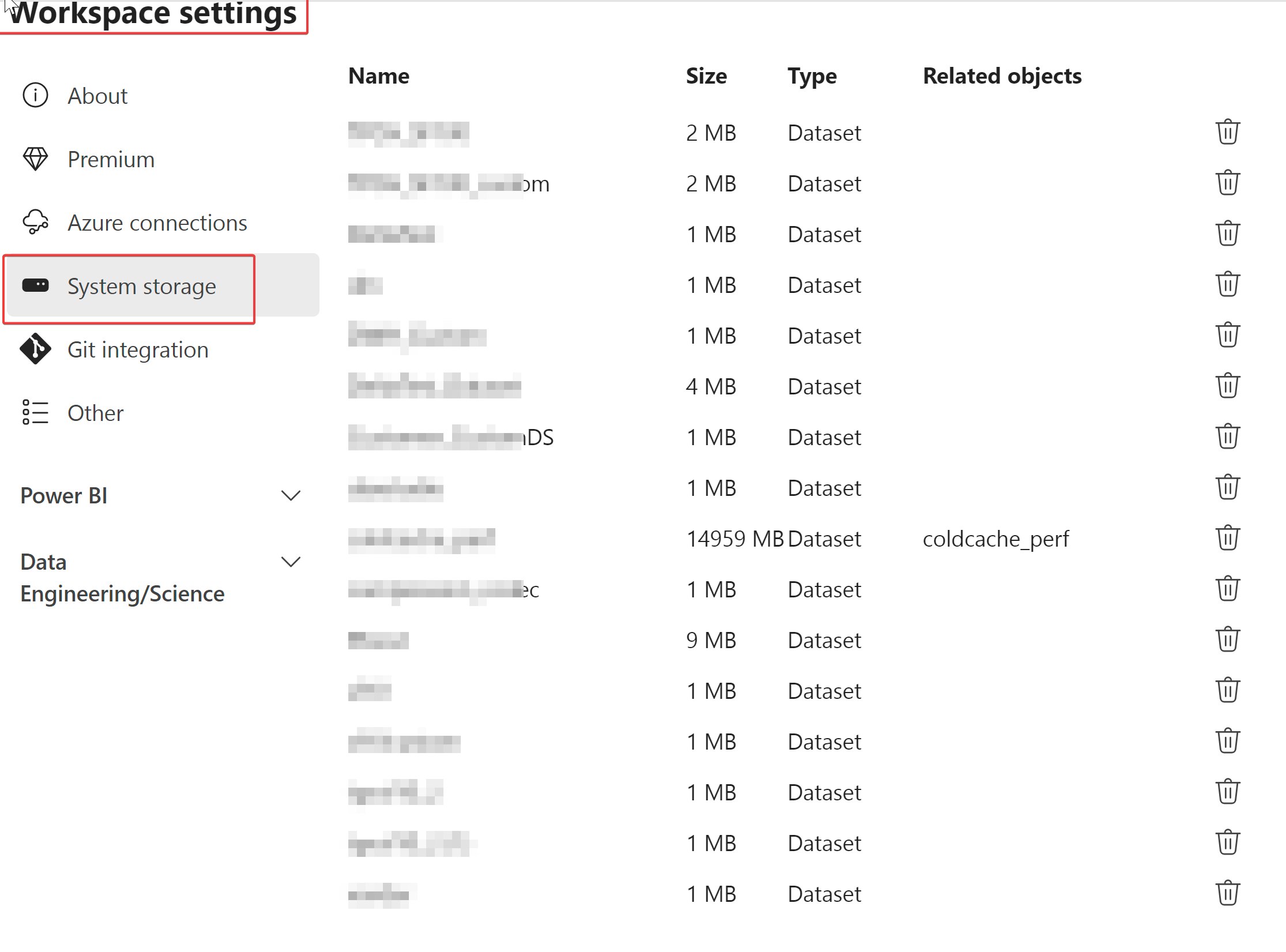
To get the semantic model size on disk, use workspace settings:
You can explicitly turn off fallback to DirectQuery by changing the TOM properties. There are several ways as below:
Power BI Service:
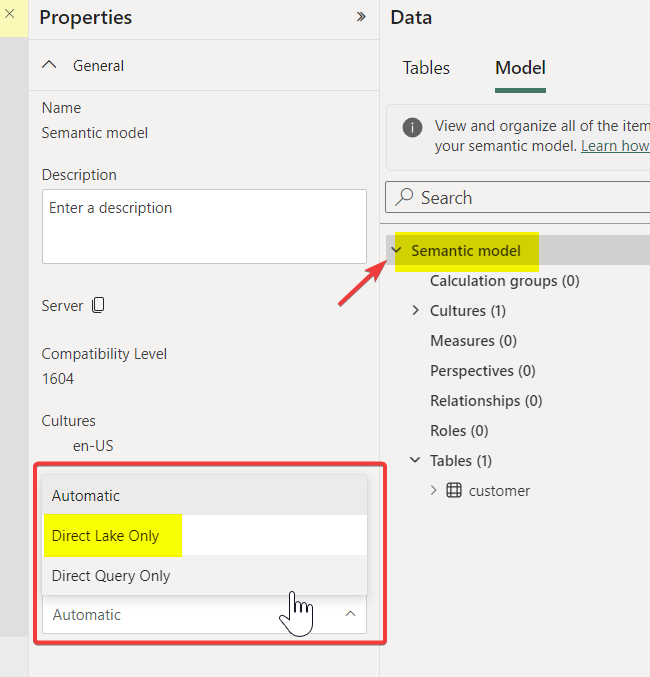
As of Feb 21, 2024, Web modeling experience in Power BI service has the UI option to change the Direct Lake fallback behavior. Default is Automatic. Read the official blog here.
Tabular Editor:
Upgrade to the latest version of Tabular Editor 2 (v2.21.1) which has the latest AMO/TOM properties. Link to Tabular Editor.
Connect to the Direct Lake semantic model using XMLA endpoint
Select Model > Under Options > Direct Lake Behaviour > Change from Automatic to DirectLakeOnly
Save the model
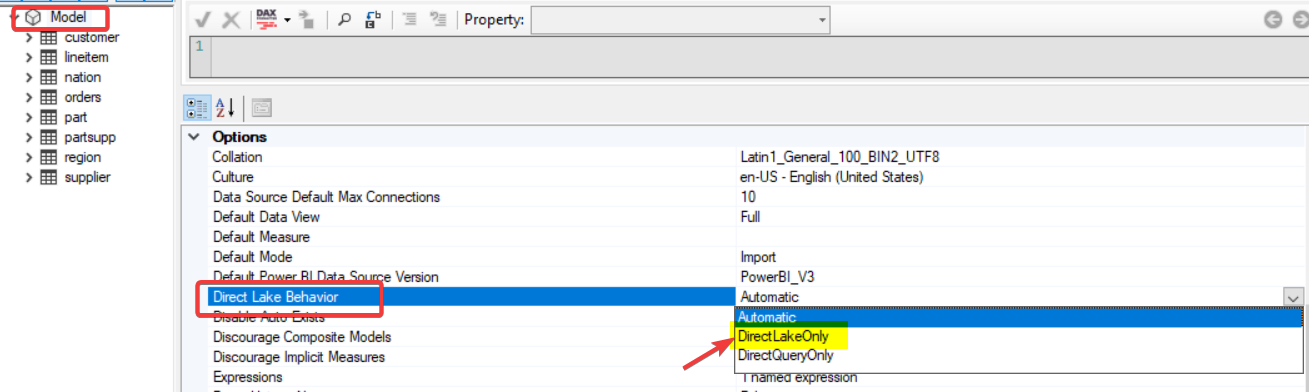
Using C Sharp
Use the below C# script
/*
Options:
DirectLakeBehavior.Automatic
DirectLakeBehavior.DirectLakeOnly
DirectLakeBehavior.DirectQueryOnly
*/
Model.DirectLakeBehavior = DirectLakeBehavior.DirectLakeOnly;
Model.SaveChanges();
SSMS
Thanks to Daniel Otykier for pointing out that the TMSL script can also be executed in SSMS to update this property. Use SSMS 19.2 to avoid errors.
Add/update "directLakeBehavior":"DirectLakeOnly" Model properties in TMSL.
Semantic Link
You can use the createOrReplace TMSL script and use semantic link >= 0.4.0 to execute the TMSL in the Fabric notebook. If you have many Direct Lake semantic models you want to update, this is a great option.
#install semantic-link 0.4.0 or higher
!pip install semantic-link--q
import sempy.fabric as fabric
ws = "<>" #workspace id or name
tmsl_script = """{
"createOrReplace": {
"object": {
"database": "Shortcuttest_DL"
},
.
.
<rest of the script>
"""
fabric.execute_tmsl(workspace=ws, script=tmsl_script)
Update 3/15/2024
Semantic Link v0.7
Semantic Link v0.7 can be used to update Tabular Object Model (TOM) properties directly in the Fabric notebook !!!
Use below function to get the list of all the Direct Lake datasets in a workspace and its respective Direct Lake behavior.
%pip install semantic-link --q
import sempy.fabric as fabric
from sempy.fabric.exceptions import DatasetNotFoundException
def get_directlake_datsets(workspace=None, return_directlake_dataset=True):
"""
Sandeep Pawar | fabric.guru
Function to get a list of Direct Lake datasets in a Fabric workspace.
Returns a pandas df
"""
#workspace of the notebook irrespective of the lakehouse attached
workspace=workspace or spark.conf.get("trident.artifact.workspace.id")
#clear TOM cache
fabric.refresh_tom_cache(workspace=workspace)
def get_partition_mode(workspace, dataset):
return any(fabric.list_partitions(workspace=workspace, dataset=dataset)["Mode"].isin(["DirectLake"]))
cols = ['Dataset Name', 'Dataset ID', 'Created Timestamp', 'Model Direct Lake Behavior']
df = fabric.list_datasets(workspace=workspace, additional_xmla_properties=["Model.DirectLakeBehavior"])[cols]
df["IsDirectLake"] = False # Initialize w/ False
for i, row in df.iterrows():
try:
df.loc[i, "IsDirectLake"] = get_partition_mode(workspace=workspace, dataset=row["Dataset Name"])
except DatasetNotFoundException:
df.loc[i, "IsDirectLake"] = "Not Found"
return df.query("`IsDirectLake` == True") if return_directlake_dataset else df
df = get_directlake_datsets(workspace="workspace")
df
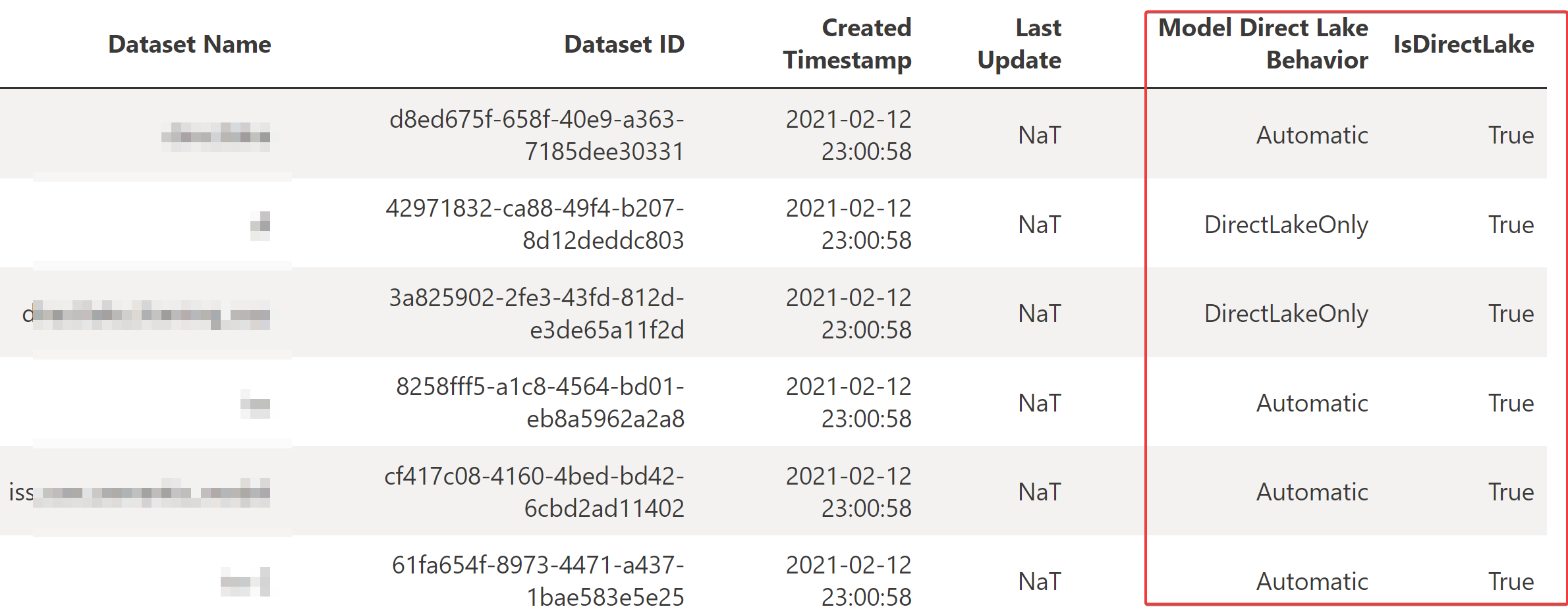
Change Direct Lake Behavior
Use below function to change the behavior of a specific model or all models in a workspace using the dataframe returned by the above function.
#Need semantic-link version 0.7 installed
import sempy.fabric as fabric
import Microsoft.AnalysisServices.Tabular as tom
#behavior can be DirectLakeOnly, DirectQueryOnly or Automatic
def change_dl_behavior(workspace, datasetname, dl_behavior = "DirectLakeOnly"):
"""
Sandeep Pawar | fabric.guru
This function updates the Direct Lake behavior, and refeshes the model
"""
#workspace of the notebook irrespective of the lakehouse attached
workspace=workspace or spark.conf.get("trident.artifact.workspace.id")
tom_server = fabric.create_tom_server(False, workspace)
tom_database = tom_server.Databases.GetByName(datasetname)
behavior = None
if dl_behavior.lower() == "directlakeonly":
behavior = tom.DirectLakeBehavior.DirectLakeOnly
elif dl_behavior.lower() == "directqueryonly":
behavior = tom.DirectLakeBehavior.DirectQueryOnly
elif dl_behavior.lower() == "automatic":
behavior = tom.DirectLakeBehavior.Automatic
else:
print("Direct Lake Behavior is invalid. Valid values are DirectLakeOnly, DirectQueryOnly, Automatic ")
return
try:
tom_database.Model.DirectLakeBehavior = behavior
tom_database.Model.SaveChanges()
fabric.refresh_tom_cache(workspace=workspace)
tom_database.Model.RequestRefresh( tom.RefreshType.Full)
except Exception as e:
print(f"An error occurred: {e}")
change_dl_behavior(workspace="workspacename", datasetname="dsname", dl_behavior = "DirectLakeOnly")
To change Direct Lake Behavior of all datasets in a workspace:
workspace = "<wsname>"
df = get_directlake_datsets(workspace=workspace)
for ds in df.query("`Model Direct Lake Behavior`!='DirectLakeOnly'")["Dataset Name"]:
try:
change_dl_behavior(workspace=workspace, datasetname=ds, dl_behavior="DirectLakeOnly")
except Exception as e:
print(f"Error with {ds}. Either the dataset is a default dataset or check permission to the dataset")
continue
Note: You will get an error if you try to change the behavior of a default semantic model. Default semantic model is always in Automatic mode and cannot be changed.
How to check if the queries are in Direct Lake mode?
There are several ways to do so. You can use Performance Analyzer to see if the query is in Direct Query or Direct Lake mode. Read this documentation for details.
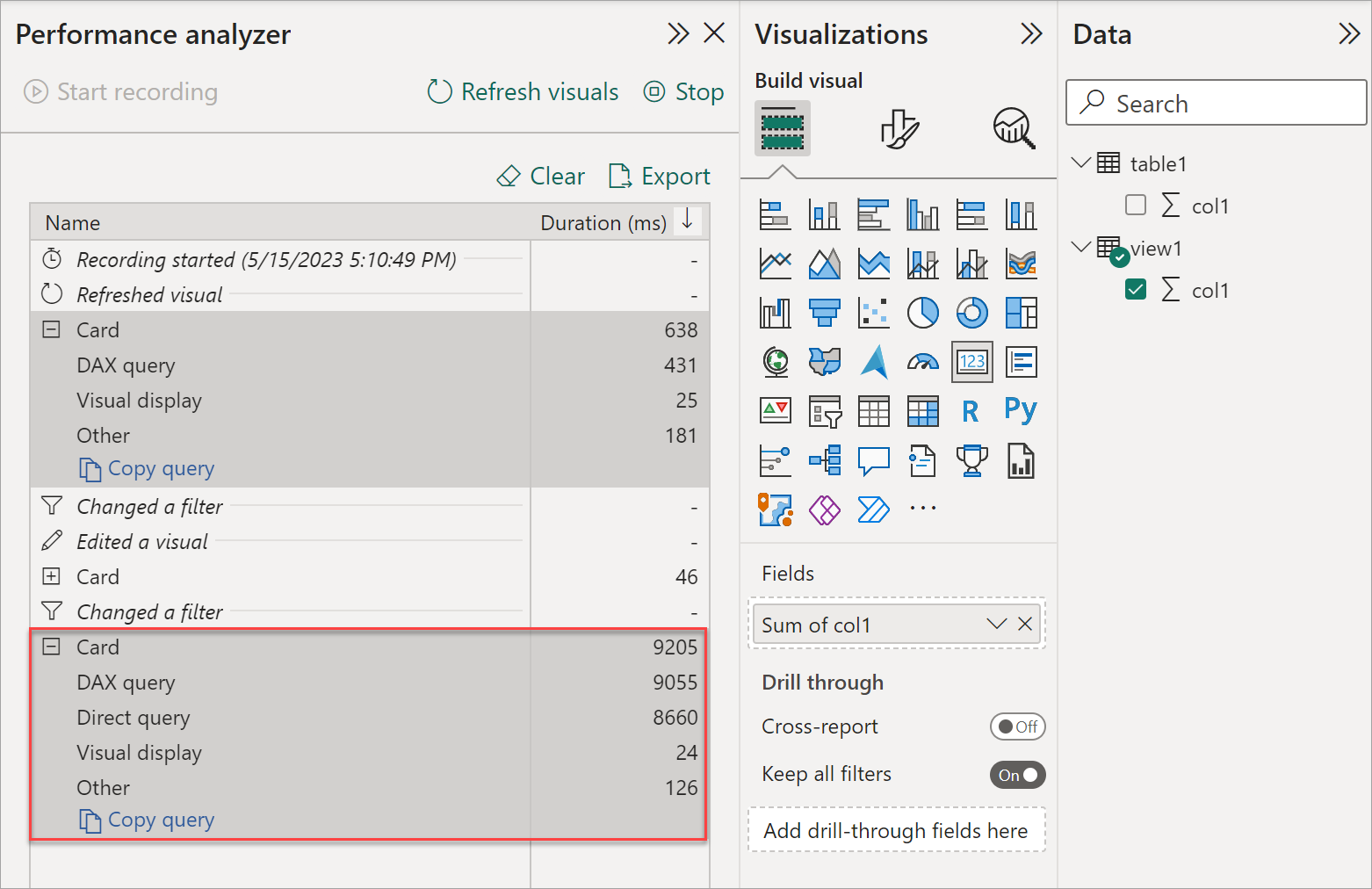
Let me show you another way to achieve this not covered elsewhere. Thanks to the latest version of Semantic Link, it's now possible to perform query tracing in a Fabric notebook. This is similar to query tracing using SQL Server Profiler or DAX Studio but using sempy in a Fabric notebook. Below is the code:
#Semantic link >= 0.4.0
!pip install semantic-link --q
import sempy.fabric as fabric
import time
ws = "<>" #workspace
ds= "<>" #semantic model
dax= """
< DAX QUERY >
"""
def trace_directlake_behavior(workspace, semantic_model, dax_query):
"""
Sandeep Pawar | Fabric.guru
Trace DAX queries to determine Direct Lake behavior of a query
Returns a tuple (behavior, dataframe with query trace)
"""
BASE_COLUMNS = ["EventClass", "EventSubclass","TextData"]
START_COLUMNS = BASE_COLUMNS
END_COLUMNS = START_COLUMNS
DQ_COLUMNS = ["TextData"]
event_schema = {
"DirectQueryBegin": DQ_COLUMNS,
"DirectQueryEnd": DQ_COLUMNS,
"VertiPaqSEQueryBegin": START_COLUMNS,
"VertiPaqSEQueryEnd": END_COLUMNS,
"VertiPaqSEQueryCacheMatch": BASE_COLUMNS,
"QueryBegin": START_COLUMNS,
"QueryEnd": END_COLUMNS,
}
try:
with fabric.create_trace_connection(workspace=workspace, dataset=semantic_model) as conn:
with conn.create_trace(event_schema, "Trace DL DQ") as trace:
trace.start()
fabric.evaluate_dax(workspace=workspace, dataset=semantic_model, dax_string=dax_query)
time.sleep(5)
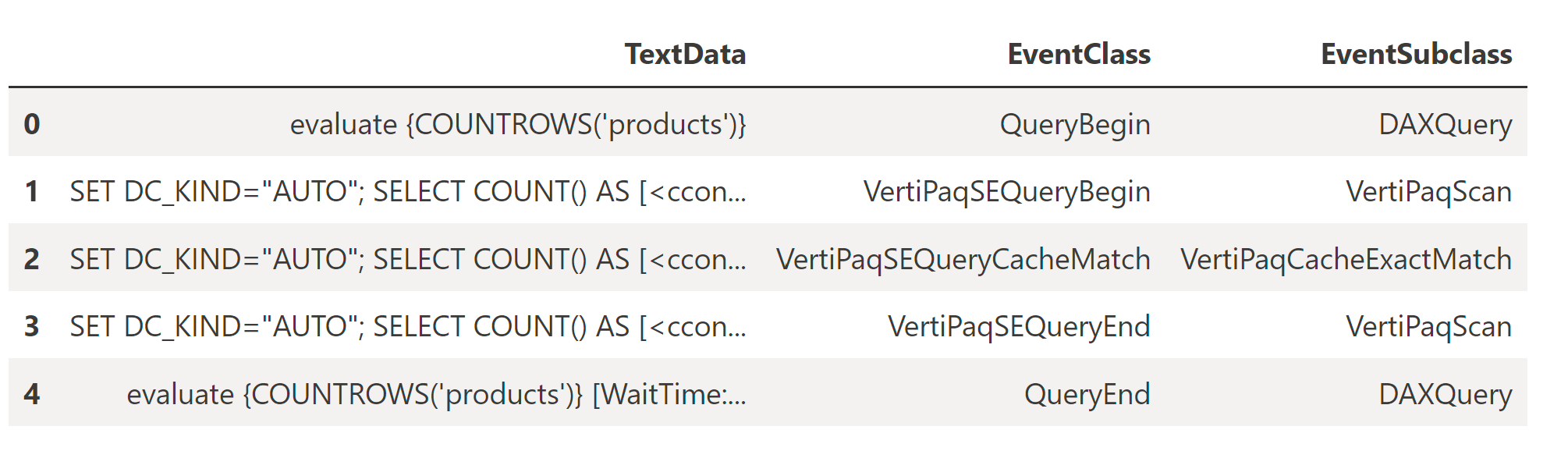
trace_df = trace.stop()
behavior = "Direct Lake query" if trace_df['EventClass'].str.contains("VertiPaqSE").any() else "DirectQuery"
return behavior, trace_df
except Exception as e:
print("Error: Check workspace, semantic model settings, DAX. Ensure XMLA is enabled and you have access to the semantic model")
raise
behavior, trace_df = trace_directlake_behavior(workspace=ws, semantic_model=ds, dax_query=dax)
behavior

Semantic Link >= 0.5.0 (Update Jan 12, 2024)
In the Semantic Link version >= 0.5.0, has a neat way to get additional properties of the model using additional_xmla_properties. This will give you Direct Lake Behavior of all the semantic models in a workspace. This is at the model level and not query.
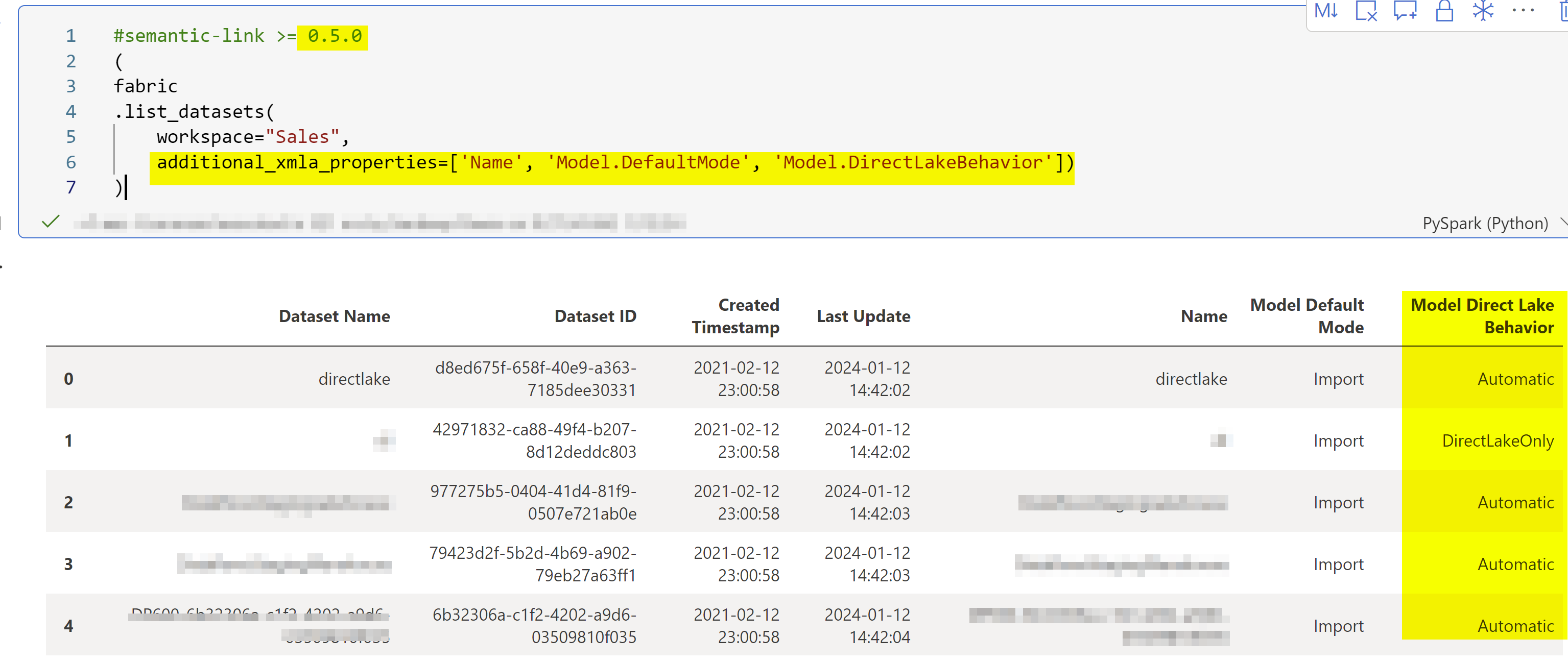
Update: 2/21/2024
Identifying The Fallback Reason
Eiki Sui mentioned on Twitter that with the December 2023 release of Power BI, you can execute the new INFO DAX functions. Thanks Eiki.
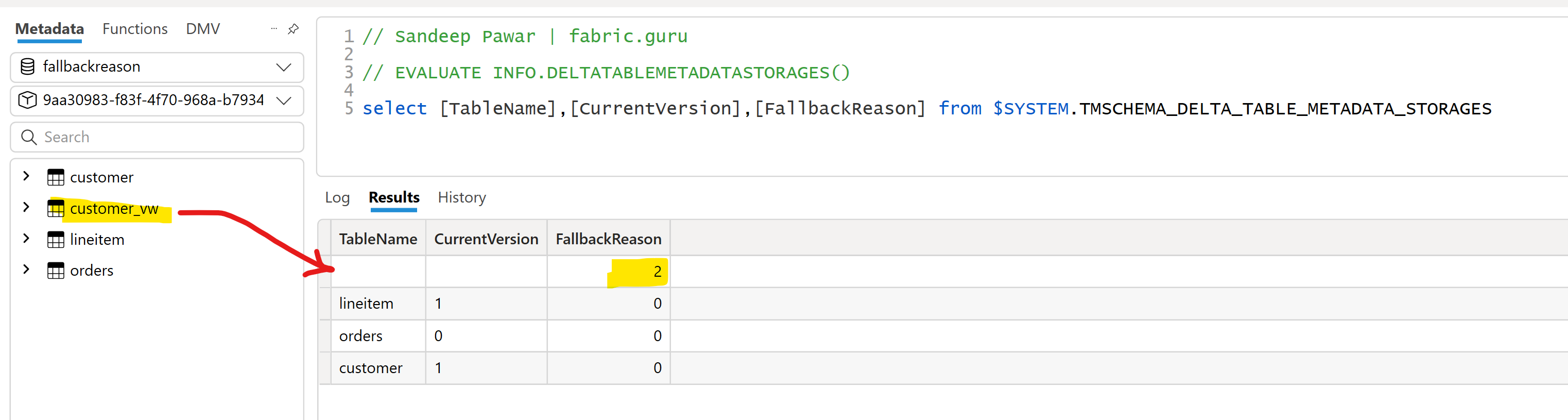
Execute INFO.DELTATABLEMETADATASTORAGES() against the DirectLake semantic model in DAX Studio and check the fallback reason. 0 is Automatic, 1 is DirectLake and 2 is DirectQuery. Note that these are the Direct Lake behaviors of the tables and not the query.
Thanks to Michael Kovalsky ( Principal Program Manager at Fabric CAT) for pointing out that the FallbackReason from INFO.DELTATABLEMETADATASTORAGES() or $SYSTEM.TMSCHEMA_DELTA_TABLE_METADATA_STORAGES can be used to identify some of the fallback reasons.
In the example below, I created a Direct Lake semantic model with three delta tables and one view. If I execute the above DMV, I can see that the fallback reason for one of the tables is 2. Since view is not a delta table, it's shown as blank.
| Reason Code | Fallback Reason |
| 0 | 'No reason for fallback' |
| 1 | 'This table is not framed' |
| 2 | 'This object is a view in the lakehouse' |
| 3 | 'The table does not exist in the lakehouse' |
| 4 | 'Transient error' |
| 5 | 'Using OLS will result in fallback to DQ' |
| 6 | 'Using RLS will result in fallback to DQ' |
Using DAX FUNCTION (Update 08/05/2024)
The above mentioned DMV ($SYSTEM.TMSCHEMA_DELTA_TABLE_METADATA_STORAGES) gives you the Fallback reason code and you have to decipher the reason. But with the new function TABLETRAITS you can get the fallback reason at the table level. In the below example, I queried a Direct Lake model in the newly available DAX Query View in the web to get the fallback reasons. One of the tables shows fallback reason as "View".


<workspace_name>/<lh/wh_name>/<table_name>. This is FANTASTIC 👌👌 because earlier it wasn't easy to identify the delta table used unless you knew the tds endpoint of all the workspaces. Being able to trace the lineage easily means we can monitor those delta tables for maintenance and optimization.Fallback Scenario:
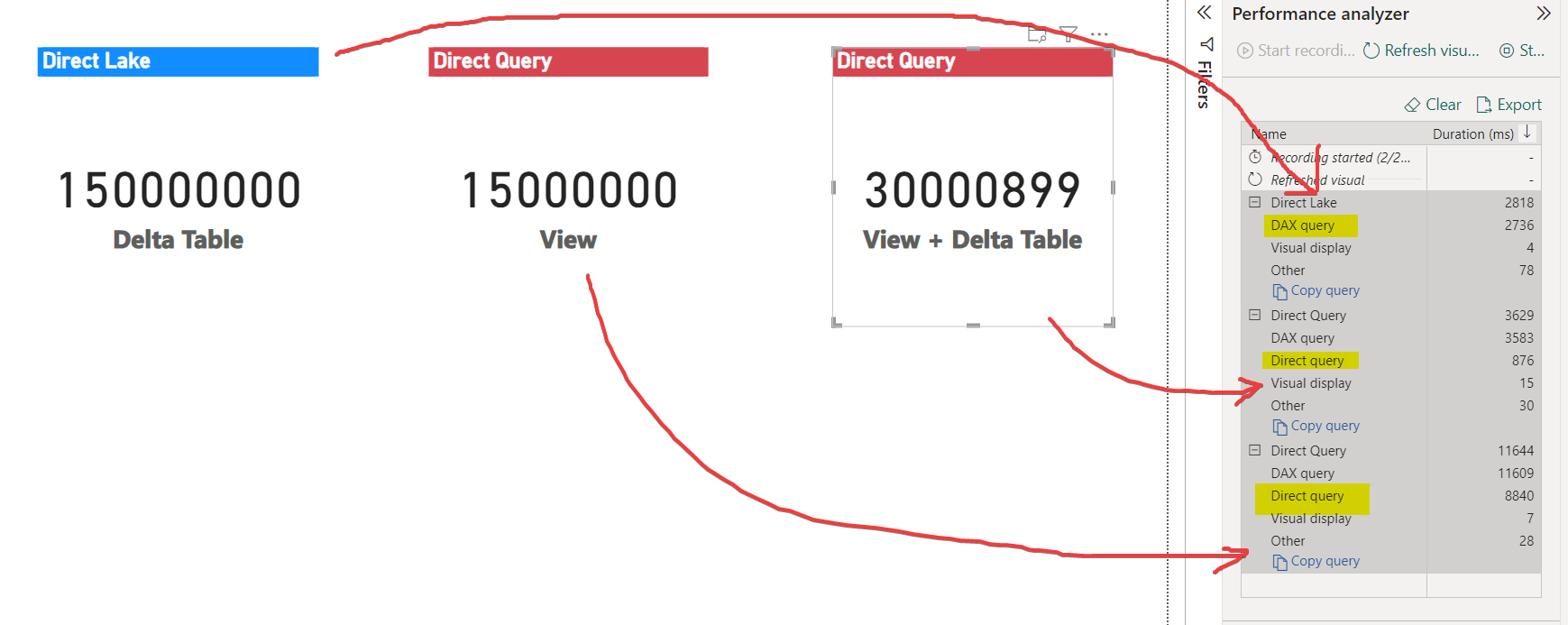
Consider the following scenario where I have two tables in the Direct Lake semantic model. These two tables have a 1-*m relationship between them.
Orders : Delta table
Customer_vw : SQL View

If I check the above DMV, it correctly shows that the Orders table doesn't fall back while the Customer table has fallback reason = 2 i.e. it will be in DirectQuery mode.

I created three measures:
Count of orders
Count of Customers
Count of Orders of customers that are in the automobile segment which will need using the relationship between the two tables
The expectation is Count of orders should be in Direct Lake, Count of customers should be in Direct Query but what about the third measure that uses a delta table and a view?
Should you change the fallback behavior?
Yes, that would be my recommendation. For a couple of reasons:
You know with certainty that the queries will always be in Direct Lake mode so you can develop and optimize accordingly.
You will likely see performance gains. When the Direct Lake behavior is set to "Automatic", two query plans are generated - one for Direct Lake and another for DirectQuery. If you set the behavior to Direct Lake, only the Direct Lake query plan will be created, hence potentially improving performance, especially for complex queries and large models. e.g. I tested a few queries on a large semantic model (>500M rows), and some of the queries were ~10% faster.
You should limit the number of rows, row groups, size and perform maintenance in addition to changing the fallback behavior.
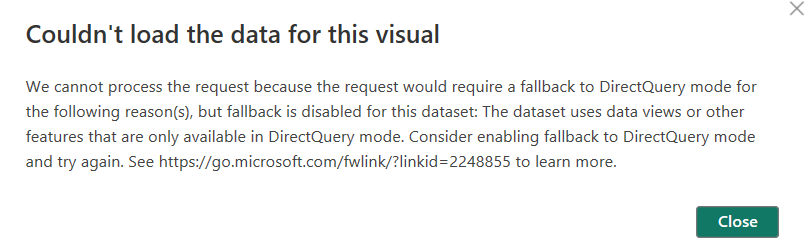
What happens if Direct Lake is not supported?
If you set the behavior to Direct Lake only but Direct Lake is not supported (see the list above), you will get an error message. This is good because you can make modeling changes accordingly. For example, if you build a semantic model using views from a warehouse, though in web experience you will see Direct Lake, but the queries are in DirectQuery. I changed it to Direct Lake only and got the below error message:
Thanks to Tamas Polner, Michael Kovalsky, Akshai Mirchandani at Microsoft for answering my questions.
Reference:
Learn how to analyze query processing for Direct Lake datasets - Power BI | Microsoft Learn
Learn about Direct Lake in Power BI and Microsoft Fabric - Power BI | Microsoft Learn
Comprehensive Guide to Direct Lake Datasets in Microsoft Fabric
Fabric/CheckFallbackReason.py at main · m-kovalsky/Fabric · GitHub